Introduction to KNIME
Let’s say you’ve been tasked to pull data from a variety of data sources on a monthly basis, manipulating and processing it to create insights. At first one may look to a powerhouse software like Informatica, but what if you don’t really need something that heavy and your budget is extremely limited? You need an ETL tool to get you from point A to point B accurately and reasonably quickly, something that’s easy to learn but has the depth and flexibility for more advanced processing and customization. Enter KNIME.
Up-front KNIME presents itself as a tool designed for data analysts, emphasizing visual clarity and usability over raw power; where Informatica will perform multiple transformation types in a single Expression node, KNIME has a node for each step. This may be a turnoff for some coming from enterprise-level software, but the enhanced control offered by KNIME is extremely valuable and can shave hours off your development and debugging. A major offering of KNIME is that it allows you to see how your data changes at every step of transformation. Because your processing steps are broken out into individual nodes you are now able to see where and how things happen. Take for example this set of nodes that perform a simple row transformation:
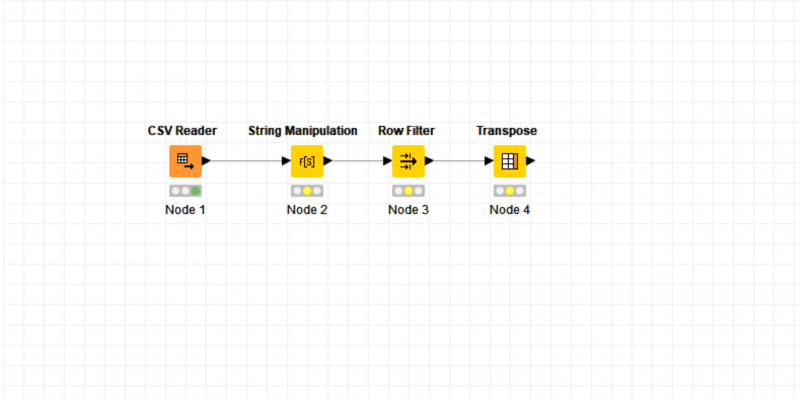
Each node after the CSV Reader is in an executable state, represented by the yellow dot. The CSV Reader has been executed successfully and has a green dot. We can open the results set and see what the data looks like:
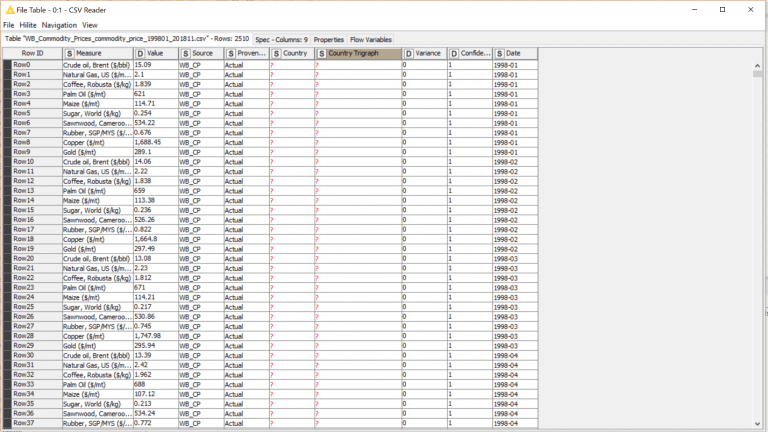
Note that it was able to pull in the column headers and give the data type without any additional processing. Though a lot of steps are more manual KNIME is very good about detecting what kind of data you’re working with; S is Strings, D is Doubles. You can alter data types with many of the other nodes in the repository, which is quite expansive:
By using the search-bar you can even find nodes by keyword or by the type of work you want to do. If we wanted to work with column manipulation, we just search for “Column”:
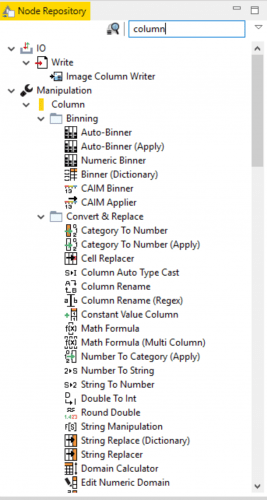
And check out how many nodes it gives us to work with! This does add on a learning curve to figuring out which node you need to use for a given process but given time and a little Google-fu you’ll land on the best way to do things.
Back to our example, the next node is going to do a simple string manipulation.
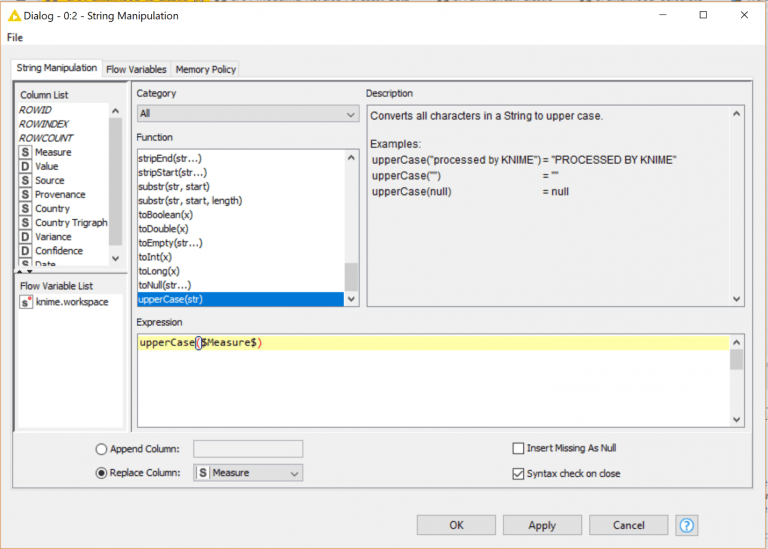
Like Informatica KNIME offers a series of functions that we can use to manipulate strings. This one is just converting the Measure column to uppercase. In the background KNIME is using Java to create these results meaning that creating your own nodes is quite easy if you know Java. KNIME even comes with a plugin to use your Eclipse IDE to create and test your custom nodes, which we have made use of in integrating KNIME with Elastic and AWS.
After the String Manipulation completes, we can again check the results:
We then follow this up with a Row Filter on getting only records with a Value of over 500:
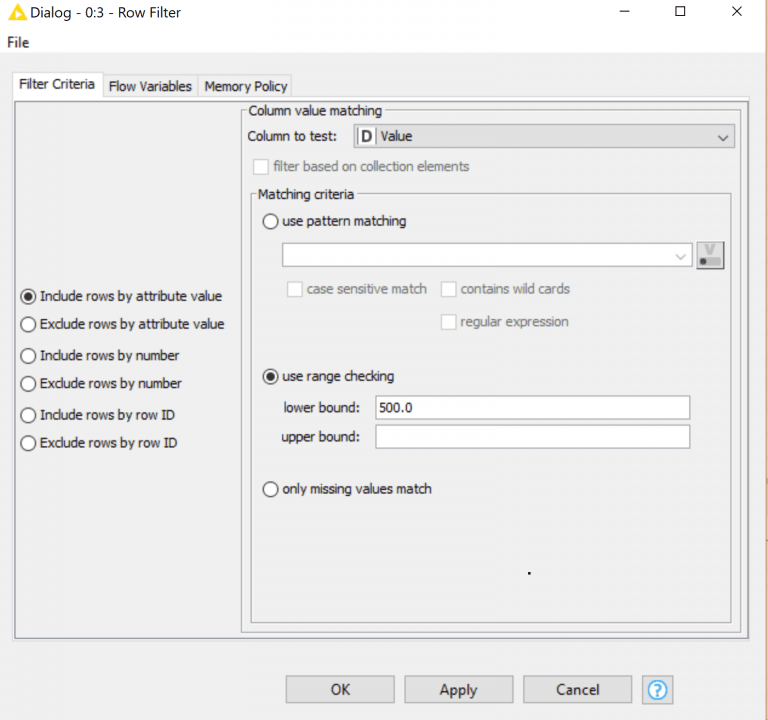
Fairly straightforward stuff here, but what if we wanted to use variables for our bounds? KNIME supports this with two kinds of variables; Workflow and Flow. Workflow variables are set in on the Workflow itself while a Flow variable is created and set during processing, very similar to what you would see in Informatica. We can see the status of our variables by checking the output tables of previous nodes and tabbing over to Flow Variables:
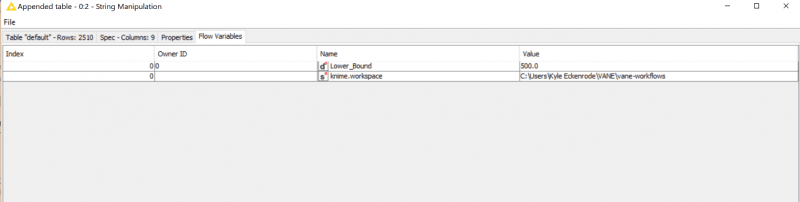
We’ve set a Workflow Variable called Lower_Bound with a value of 500.0. Now when we go into our Row Filter we can use that variable to set our lower bound in the Flow Variable tab of the Node Configuration dialog:
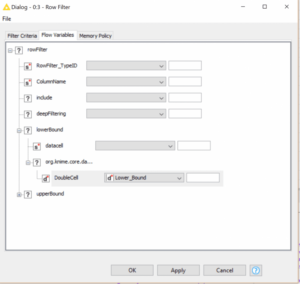
Post-execution we get these results:
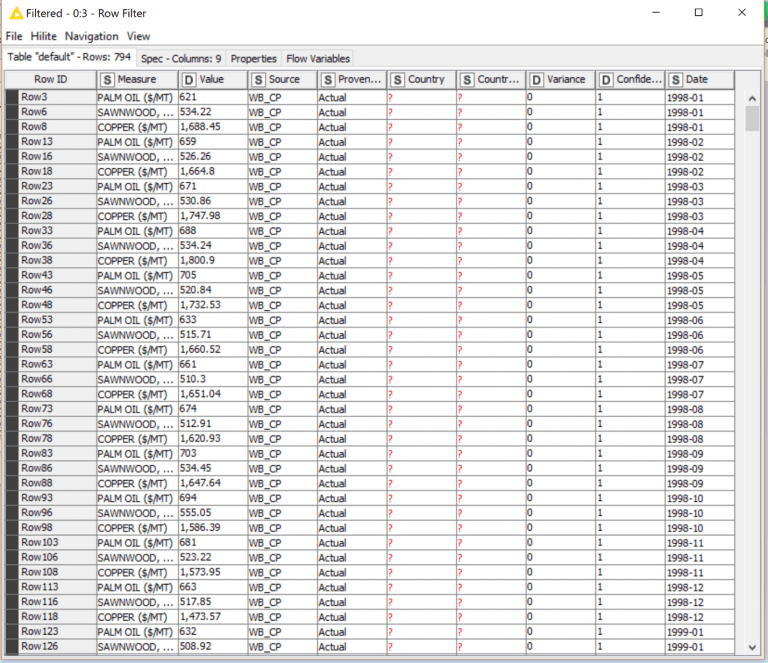
Now let’s say we want to manipulate that variable and add 500 to its value. We can use Variable nodes to alter the state of both our Workflow and Flow variables, which use a different input port type than a normal node. Note the red circle icons on this Math Formula node:

Red circles represent variable inputs and outputs and can be linked to and from other variable or normal nodes by their variable ports. These are normally hidden by the UI but can be dragged from if you click in the upper-right corner of a node for output or upper-left for input. You can also expose them by right-clicking and selecting “Show Flow Variable Ports”
We can now connect a normal node to a variable node or pass variables between them. Here we’ll use this to connect to the Math variable node so that it can execute:
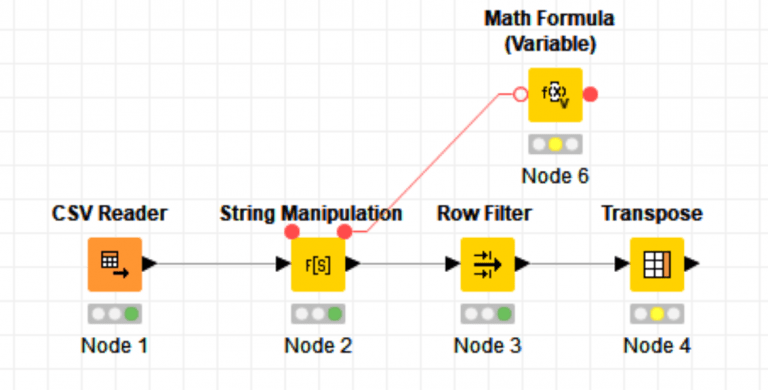
In the Math node we’ll add 500 to the Lower_Bound Workflow variable. This will not overwrite the value in our configuration, it will only alter it going forward in the workflow. We could use this to do another Row Filter or any other set of operations now parallel to the rest of the nodes, but we’ll continue on with the Transpose node:
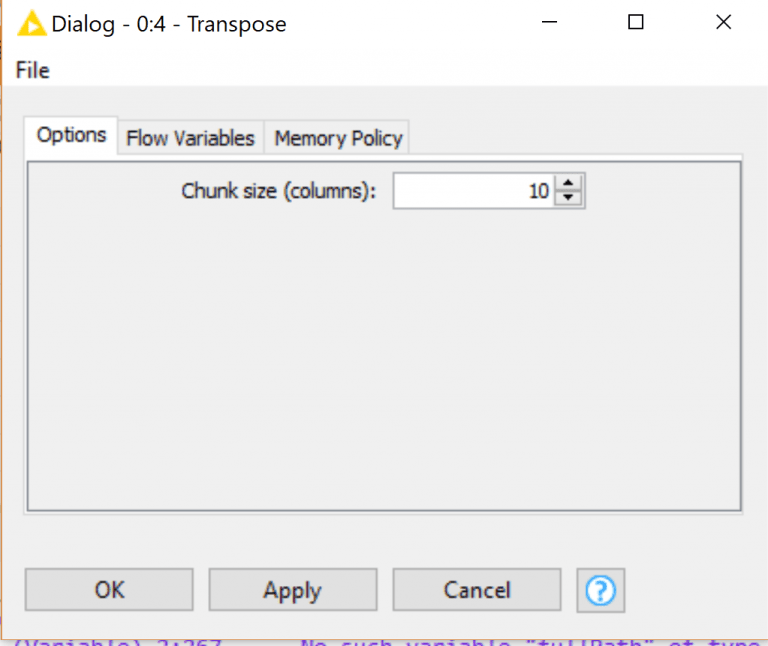
The Chunk Size is the maximum number of columns the node will be looking to transpose. 10 is the default which is more than the columns we have going in, so we’ll keep it at 10. Post-execution we have this result:
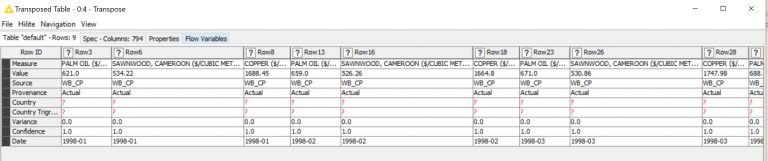
You can scroll left and right here, I’ve cut off the bottom to save space
The line is red as we hold the new node over it…
Choose OK…
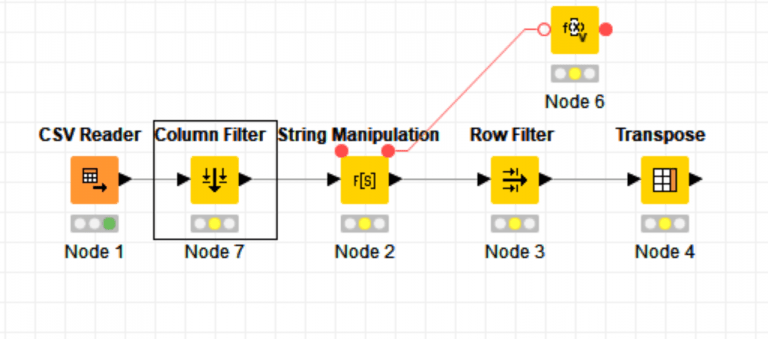
All we need to do now is configure the node to filter out the columns:
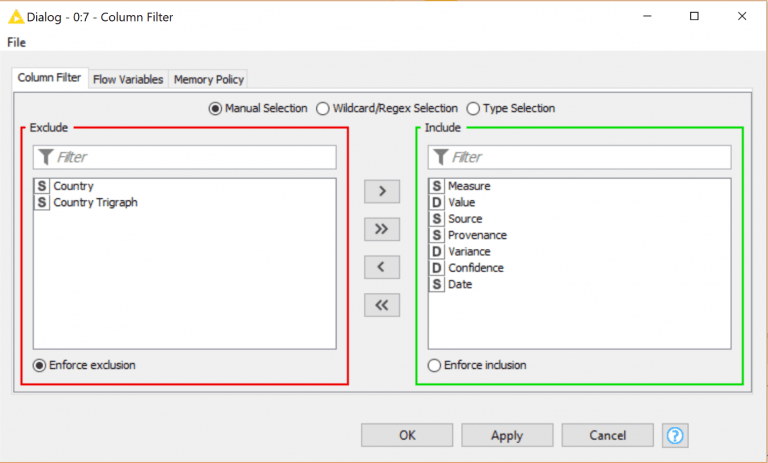
After executing the rest of the pipeline, we end up with our final result:
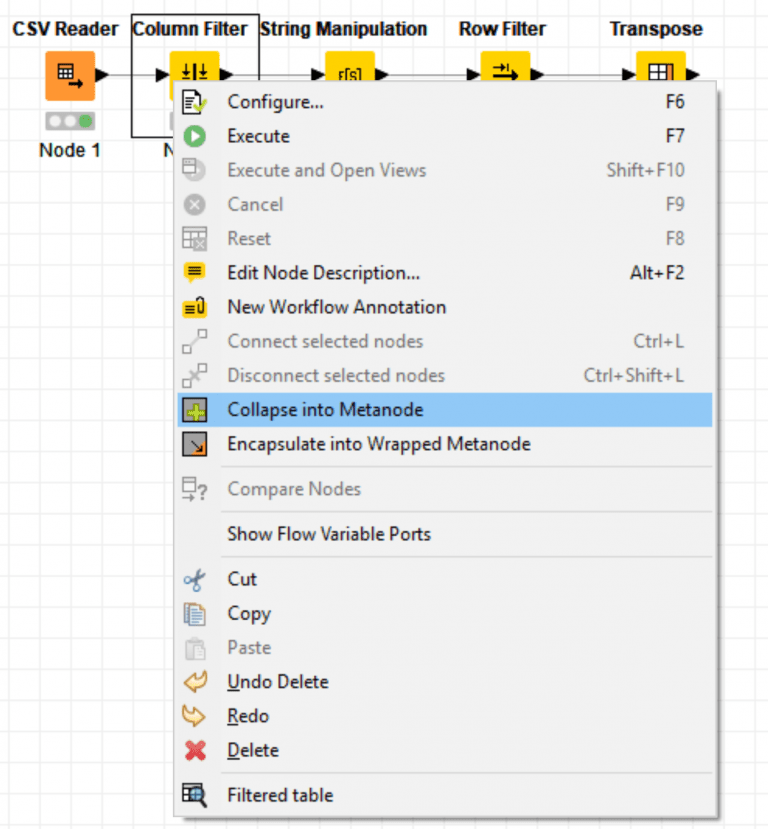
If we wanted to consolidate this process, we can just make these steps into a Metanode:
We can enter this Metanode to see the processing steps and check the individual steps:

While this is all possible in bigger ETL software it is certainly not as easy as KNIME makes it, and we can fully control how and when every step happens. Some jobs are suited for enterprise-level ETL but when you need something lean and precise KNIME is a fantastic choice with minimal startup time. The installation process is quick and easy and KNIME offers a great package of example and practice workflows. If you’re a Java developer there’s a lot to be gained from learning how to customize and create your own nodes, as well as many node packages created by other KNIME users for you to try out.

