Leveraging Athena with KNIME in a Robust Manner, Part 2
In my previous blog posting, I introduced an issue we were having with seemingly random intermittent failures using Amazon Web Services’ Athena backed by a large number of data files in S3. The issue was arising because S3 is eventually consistent and occasionally queries were being executed before their underlying data files were fully materialized in S3.
Our solution was to introduce try/catch Knime nodes with a loop to retry failed queries a few times in case of intermittent failures. To do this we had to do our own flow variable resolution in the Athena SQL queries since the standard Knime database SQL executor node does not do variable substitution when the query is configured via a flow variable. My previous blog posting (link to part 1 here) covered how we resolved embedded flow variable references in a Java snippet node.
In this blog posting I am going to cover the workflow we use for the actual query retry logic so that we retry each query a given number of times until it either succeeds or we have to abort the workflow processing. This workflow logic was done by my coworker, Alex To, and based on a post he found in the Knime community forums.
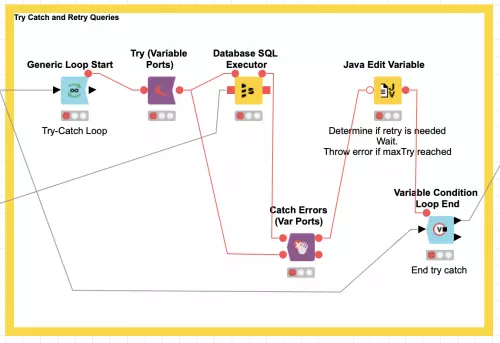
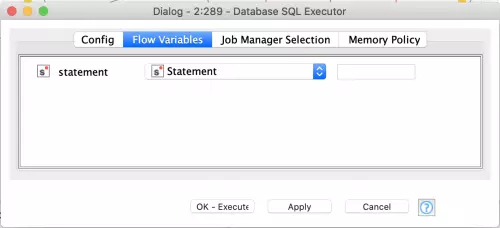
The snippet above shows the retry loop surrounding the try/catch block that is used to execute a single SQL statement at a time (the outer loop that executes all statements sequentially is not shown). The Generic Loop Start and Try (Variable Ports) nodes are set with their default configuration. The Database SQL Executor node is simply configured to use a flow variable for the statement to execute as follows:
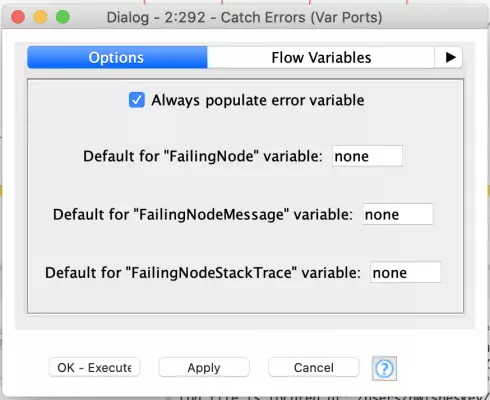
For the Catch node, we want to configure it so that the error variables are always set so that they can be tested to determine if the SQL execution succeeded or failed:
The core of this technique is the retry logic which is built into the Java Edit Variable node which immediate follows the Catch node:
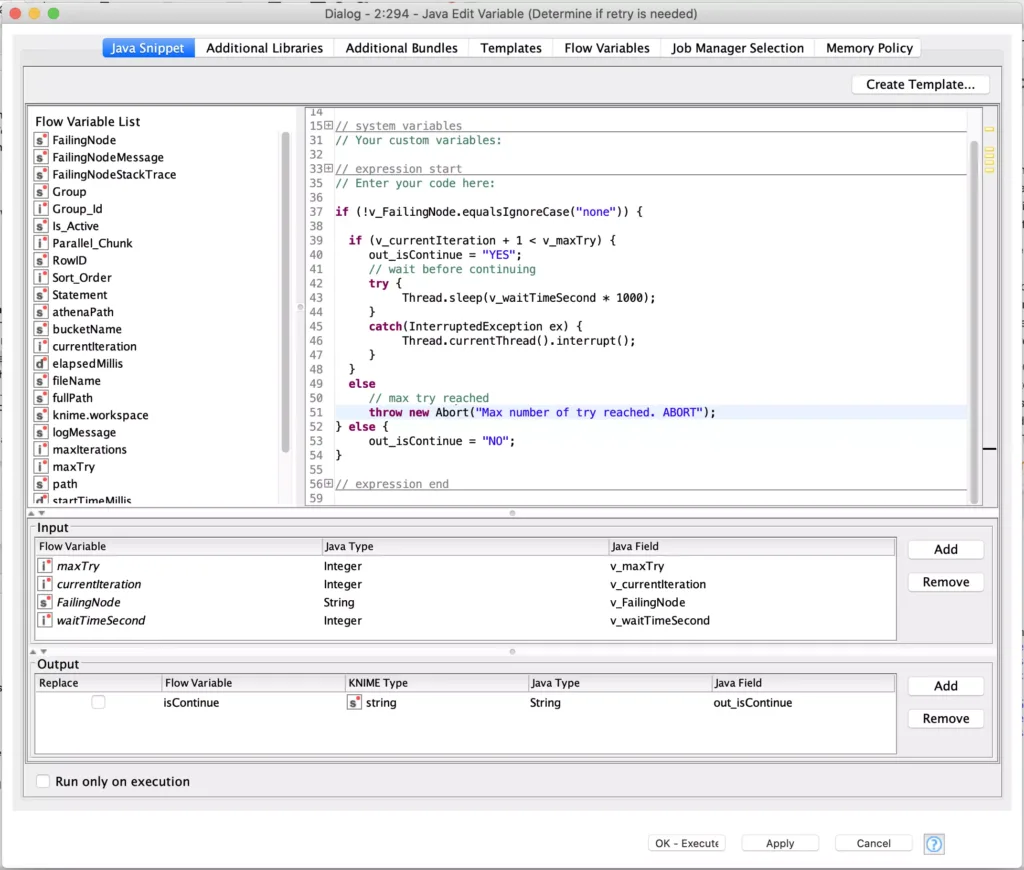
Any error that occurs (e.g. the Catch node variables are not set to their default values of “none”), will cause the if statement to trigger. The conditional block uses flow variables to keep count of the number of tries in the currentIteration flow variable (which was initialized to zero in an upstream node). The maximum number of retries is also configured in a previously initialed flow variable, maxTry.
If we have not reached the maximum number of tries, the node will sleep for the number of seconds configured in the waitTimeSecond flow variable before allowing execution to proceed to the next node. However, if we have reached the maximum number of attempts, the workflow will be aborted by throwing an Abort exception. It is important to note that the technique of throwing this exception to stop executed is only supported in Knime 3.7.2 and later versions.
The final piece of this workflow snippet is the Variable Loop Condition End node which is configured to use the value of the isContinue variable to decide if the loop needs to execute again. This variable is set in the Java snippet’s retry logic based on whether or not an error was detected from the SQL execution node.
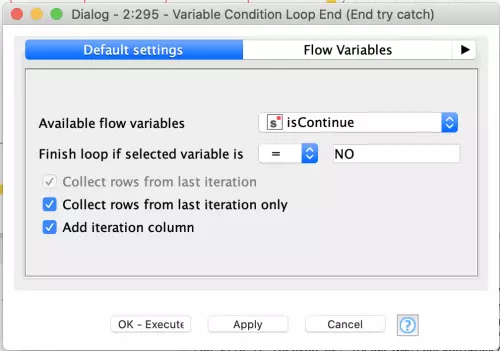
This completes the workflow snippet and shows how to support robust execution of AWS Athena queries using KNIME. Furthermore, it demonstrates power of the Try/Catch KNIME nodes and the surrounding retry logic which can be generalized to make KNIME workflows much more robust in any environments where there may be intermittent failures in things like file transfers, resource locking, etc.
