Bulletproof Your KNIME Workflows with System Property Variables and External Config Files
KNIME workflows can contain a lot of code and, like all good programmers, I always want to eliminate as many code changes as possible. To accomplish this optimization, I rely on the use of table-driven processes, external property files and system property variables. The use of these techniques can reduce code changes and ensure that workflows will work on different computers that are not setup identically.
I’d like to begin by discussing table-driven solutions. For this type of solution, I will use the data in the table to make the change. This can be done by simply changing the value of an attribute. For example, if I wanted to ensure a document was processed, I would add a flag (doc_processed_fl) to the document table with a default value of FALSE and have the program set the value to TRUE upon the completion of the process. This way I am assured the record will be processed. In the event of a catastrophic failure (network error, database error, etc.) causing the workflow to be halted, the flag is not updated and therefore can be processed on the next run with no updates. If there were records we didn’t want to process for some reason we could update the flag upon insertion or before the workflow runs to avoid these records.
Another example of a table-driven solution is similar to the to use of external property files and system property variables. In all of these solutions you use a key/value pair to ensure the process is working as expected. The database solution should be used for data centric challenges, where the external property files and system property variables should be used for more environmental changes. Let’s take a deeper dive into the use of external property files and system property variables for the rest of this blog.
Let’s move our focus to system property variables. Although we try to make all of our systems exactly the same there are often little nuances which make each computer environment a little different. Let’s assume for this example we want to output our data to the default user directory. On one of my computers the default directory is C:Usersjmchugh while on another it is C:UsersJim McHughKNIME. If I hardcode the output location in my CSV Writer then I may end up with an error since the other computer does not have the same directory. What if I want to move my process from Windows to Linux? Do I want to go back and re-code all of my workflows? Of course not. This is where the system properties table comes into play. Let’s take a look at an example using KNIME.
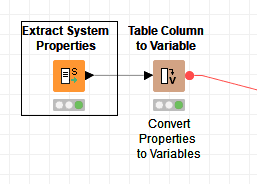
Figure 1
Figure 1 shows two KNIME nodes used to extract the system properties from the computer and covert the extracted data into flow variables. Looking into the Extract System Properties node (Figure 2) we see that we can choose the system properties we want to use for the workflow.
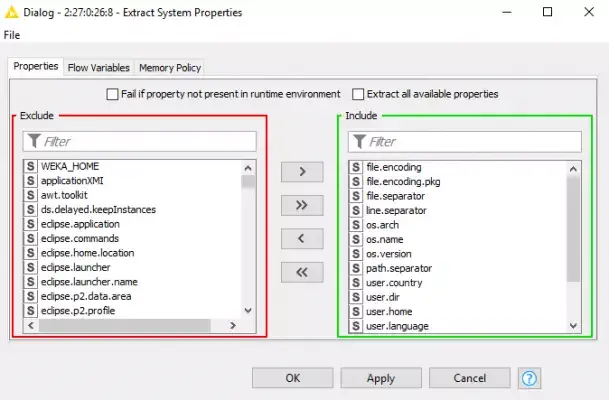
Figure 2
This provides a list of key/value pairs (see Figure 3).
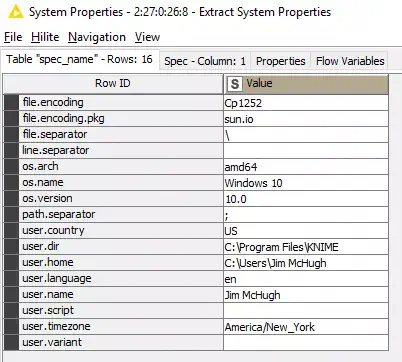
Figure 3
We need to convert these key value pairs into flow variables we can use in the rest of the workflow. To do the we use the Table Column to Variable node. All we need to do here is make sure the Column Name is set to Value (Figure 4).
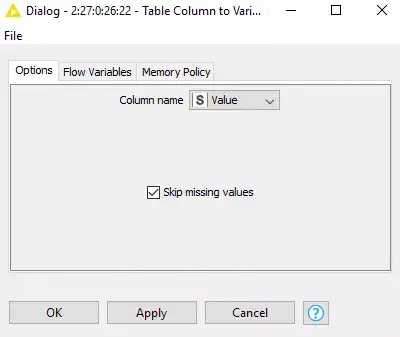
Figure 4
That is all we need to do to make all of the selected system property variables available to workflows as flow variables. I save this as a wrapped metanode and then export this as a template. I can reuse this functionality over and over without rewriting or copying the code. Just drag and drop and I am ready to go with the system property variables I need!
Now let’s look at external property files. I use external property files to store connections to databases or some other relatively static data which is used by the workflow. In some situations, although the data inside the config file changes, I do not want to make code changes. The most common example is when we move from development to test and from test to production. In these instances, our database connection will change but we do not want to change our code so we store this information in a secure file in the same location on each server. The file will contain different connection information in each file based on the tier of the server (development, test, or production). Let’s take a look at how we would retrieve this information using KNIME.
First, I use the system property values I discussed above, so that I can be assured that the file location is where I expect it to be and it can be run regardless of the operating system or default directory. All I did was drag it on to the workflow palette and connect it to the Java Edit Variable (Figure 5).

Figure 5
Here, in the Java Edit variable node, I combine variables to make a new variable (Figure 6).
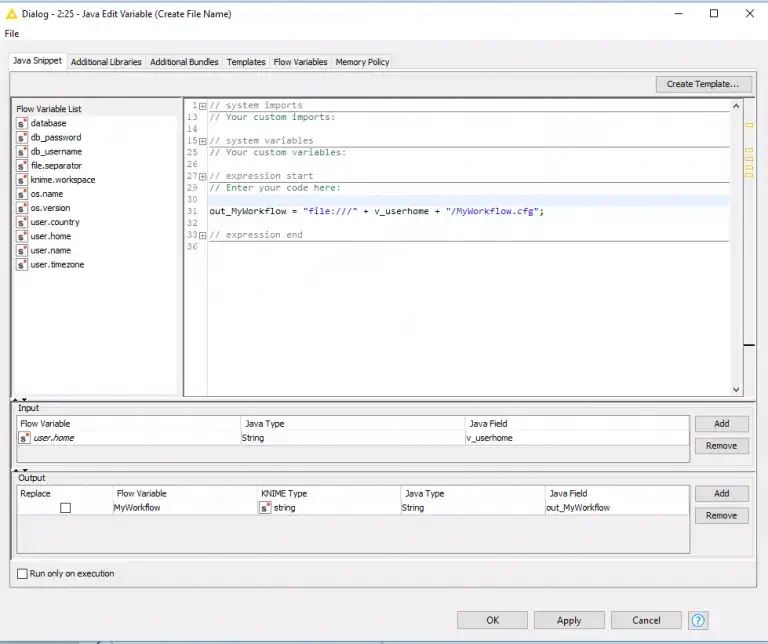
Figure 6
Now that I have the location and name of the configuration file, I can pass it as a variable to the File Reader node. Here in the File Reader node we need to make some modifications to the defaults. First we need to make sure that we have the following Basic Setting checkboxes checked: read row IDs and read column headers. The other thing to verify is the Column Delimiter drop down. Now move to the next tab or click the flow variable button next to the file location and use the flow variable you created in the previous step. (Figure 7 and Figure 8)
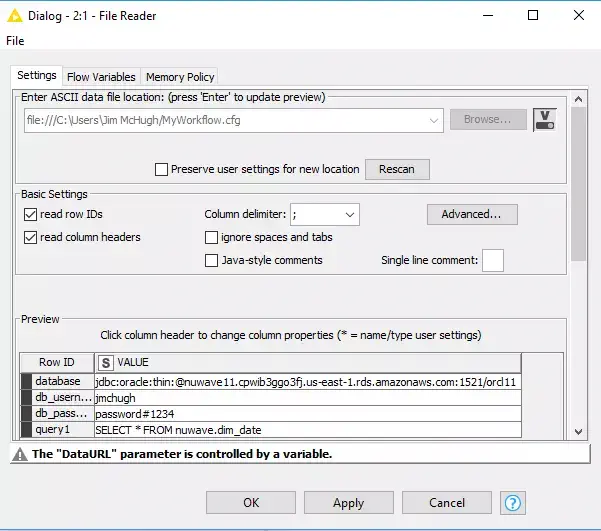
Figure 7
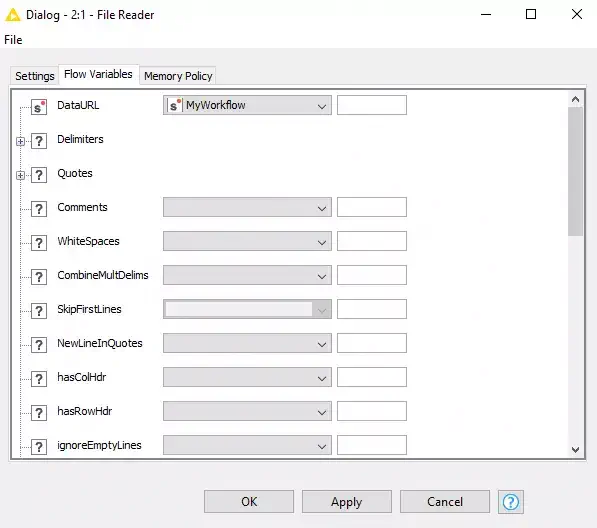
Figure 8
This will read the file and create a list of key/value pairs which I will convert into variables in the next step of the workflow using the Table Column to Variable node just as I did in the system properties workflow. Now all of the data stored in the configuration file is available as workflow variables. Figure 9 shows how I use the flow variables to connect to the database and Figure 10 shows how I pass the SQL into the Database Reader node.
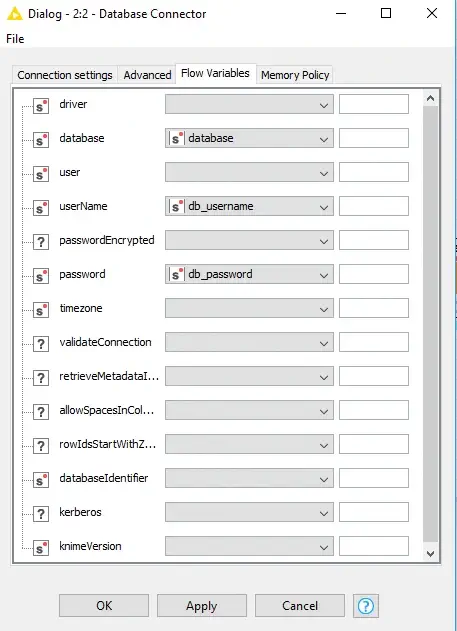
Figure 9
Figure 10
Now you have a robust workflow solution that will work on multiple servers and in different environments and making modifications is as simple as changing a configuration file.

