Embedding Data Files in KNIME Workflows
When developing stand-alone workflows for my past KNIME related blog entries, I’ve often distributed their associated source data files by embedding them right in the workflows themselves. I do this based on a little trick I learned when I came across an old KNIME forum post talking about the technique. While I’ve seen other workflows using this technique, I have not seen a step-by-step guide on how to do it. So, for this week’s blog posting, I thought I’d show you how.
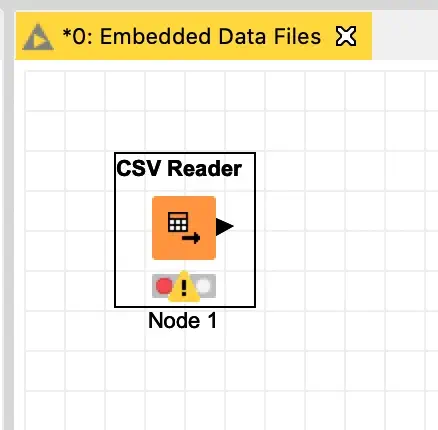
While this technique works for any of the file reading nodes, I am going to assume I have an existing workflow that reads a sample CSV file that is located on my desktop. To embed this, I need to copy it into a special folder inside the node’s configuration directory in my workflow’s save location. The easiest way to find the workflow’s save location is to right click on the workflow in the KNIME workbench’s explorer and select the “Copy Location” menu item and then select “Local path” from the sub-menu:
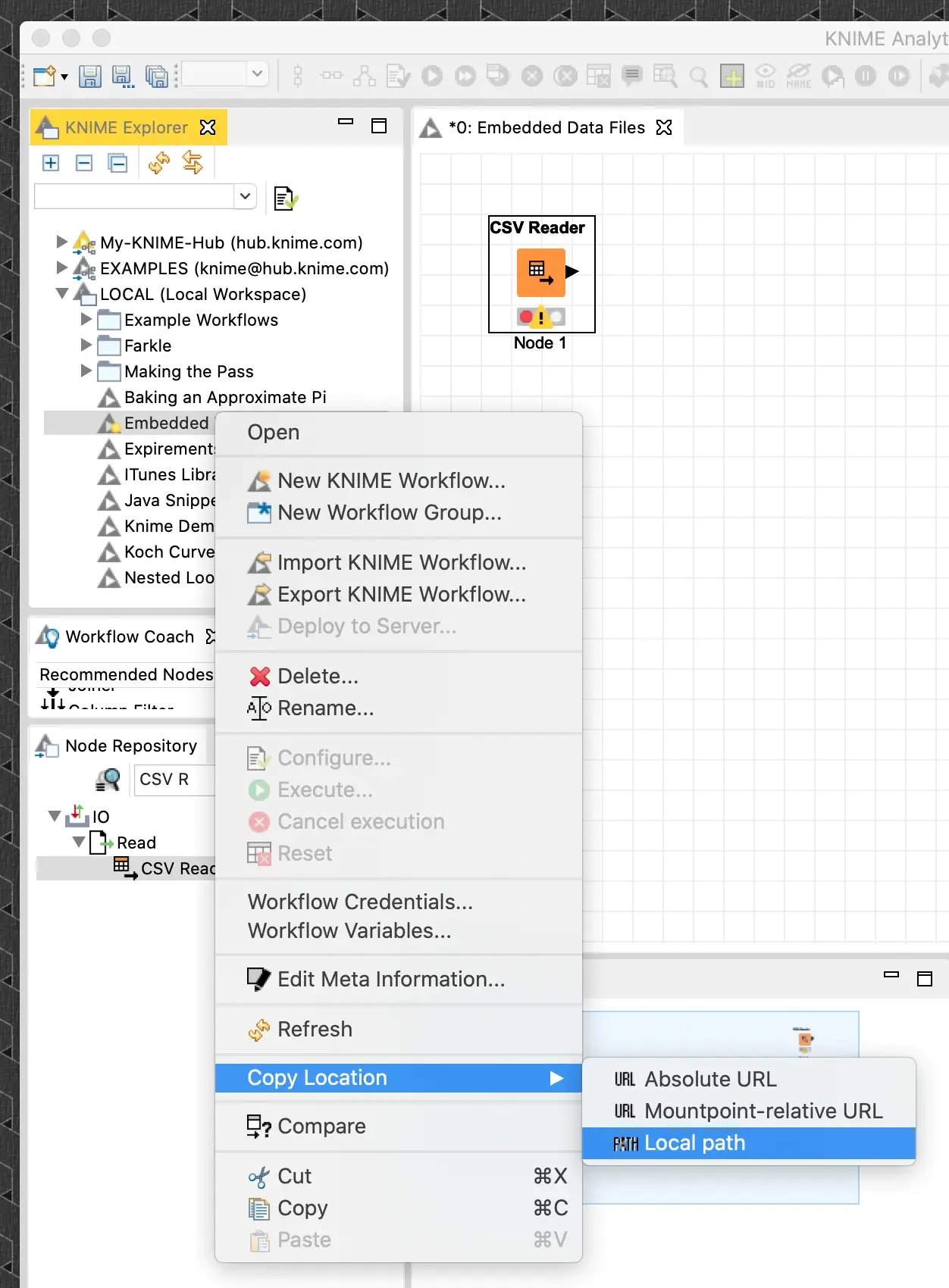
This copies the location of the workflow’s save directory to the clipboard so that it can be pasted into a change directory command in your shell:

Now that we are in the workflow’s save directory, we need to find the directory for the CSV Reader node’s configuration files. KNIME names the directories based on their node type and a unique node id number so if you have multiple CSV Reader nodes, it can be a challenge to find the specific node’s directory. To make sure I have the correct node, I enable the workbench option (located in the toolbar) to show the node identifiers in the node titles:

The title of the node is now the same as the node’s configuration directory:

To include a data file with the node’s configuration information, the data file must be copied into a subdirectory named “drop” in the node’s configuration directory:

Now that the data file is copied into the workflow, we need to edit the node’s configuration twice in order to access the embedded data file. I am not exactly sure why it is necessary to edit the configuration twice, but my guess is that the configuration directory of the node is not rescanned until the first configuration edit is saved. For the first edit, I just open the node’s configuration dialog and change the source file so that the dialog has to save its configuration when I close it:
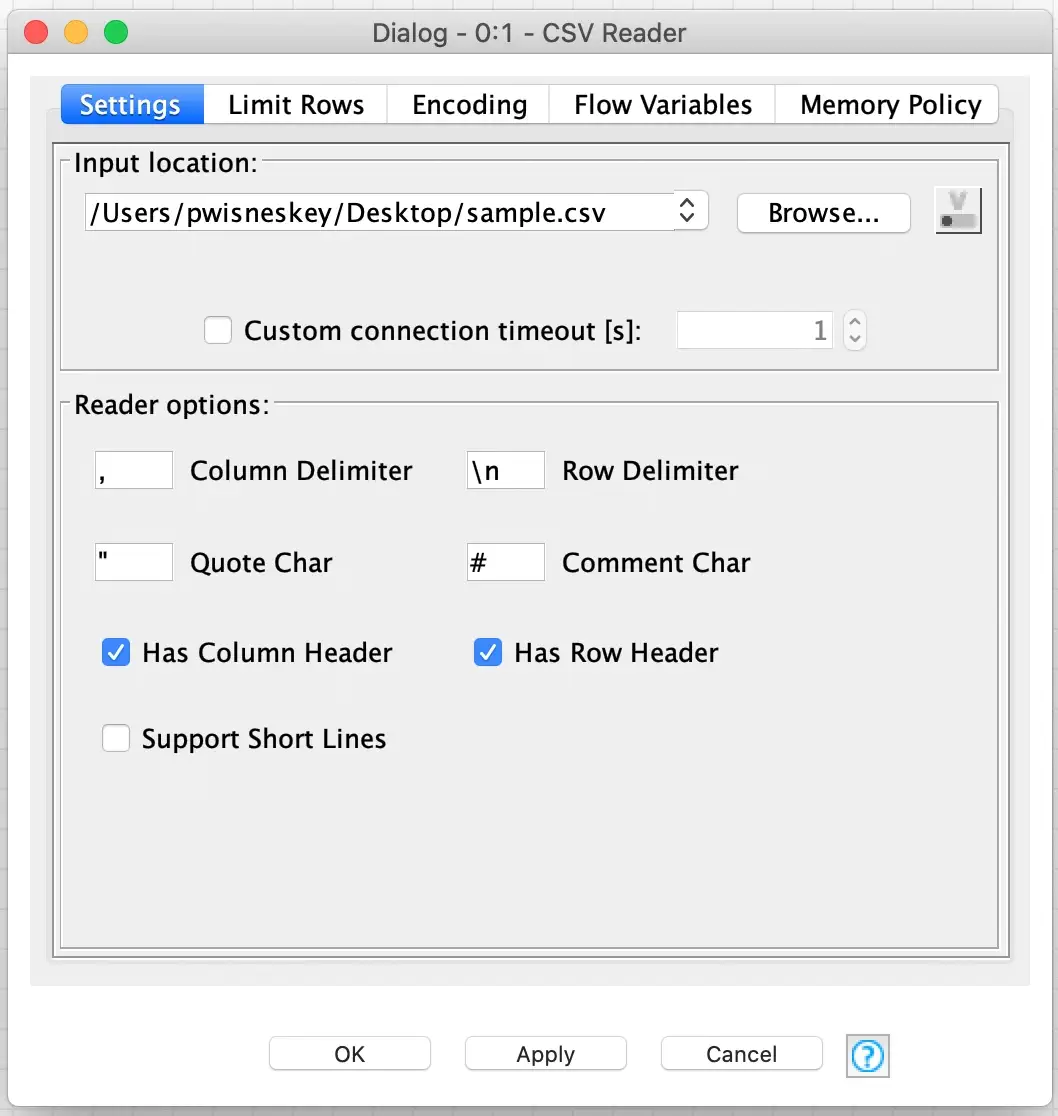
After that configuration is saved, I then immediately open the configuration dialog and this time there is a special flow variable available that is automatically configured with the name of the embedded data file.
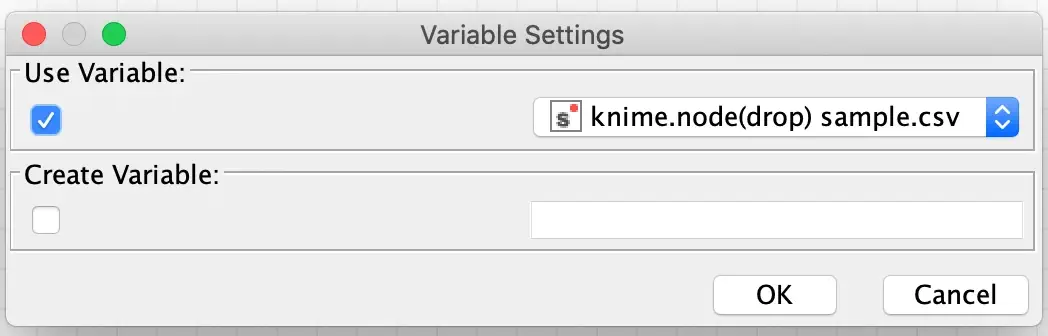
It is then just a matter of binding this flow variable to the “Input Location” setting in the dialog (which is called the “url” parameter internally):

Now, when the node is executed it will use the embedded copy of the data file. Furthermore, this data file will stay with the workflow when it is exported or shared to the KNIME Hub. Embedding data files like this makes it easy to share self-contained workflows with no external dependencies that need to be resolved before they can be executed.
