Loading Transaction Fact Tables
This blog post will focus on loading transaction fact tables, subsequent posts for periodic and accumulating snapshots will follow in the coming weeks.
Loading fact tables is very different than loading dimensions. First, we need to know the type of fact we are using. The major types of facts are transaction, periodic snapshot, accumulating snapshot and time-span accumulating snapshots. We also need to know the grain of the fact, the dimensional keys which are associated to the measurement event.
Let’s say we want to measure product sales of by customer, product, and date attributes. The source transaction system may provide the following associated dimensions: DIM_CUSTOMER, DIM_PRODUCT, and DIM_DATE. Here is an example of a set of product sale transaction records:
[insert table]
Here is what the dimensional star schema would look like:
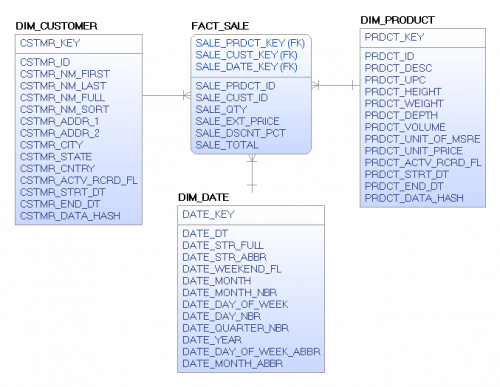
For an event like this where we receive independent transactions, we would simply sum the appropriate columns grouping by our natural key attributes, retrieve the appropriate dimensional key values, and load the transactions into the fact table. In this example none of the dimensional attributes can change, therefore once the fact data is inserted it will remain unchanged.
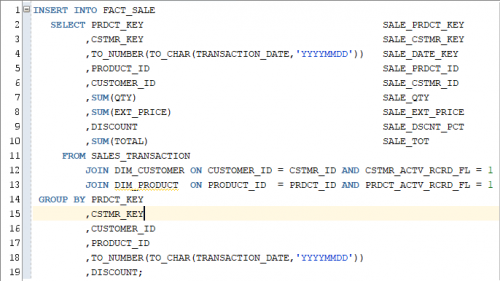
Now, let’s look at a slightly different scenario. Our customer, the Department of Labor Statistics, wants to track the unemployment rate by state on a monthly basis. They note that sometimes they need to go back and revise the numbers for previous months and they want to be able to see these individual transactions as they change the measures.
We could create an accumulating snapshot which would take more processing power to create and maintain and would miss the transactions that change the rate. Therefore, because they want to see the detailed transaction as it changes the measures, we will use a transaction fact to capture this data. Let’s take a look at how this table might be designed.

As you can see, this fact table is very different than the sales fact defined above. Because we are trying to capture daily changes at a monthly level, we need to add several supplementary columns. We added audit columns, similar to those we use in dimensions to allow us to track the changes in the data. We have also added a flag (active monthly record flag) to indicate which record is currently active for the state and month and a load date key to ensure the data is unique. These columns are necessary to help us meet the requirements provided to us from the customer. Finally, to effectively load our data on a daily basis we will need to do some additional processing which will require a staging fact table.
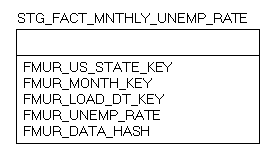
Let’s walk through the processing steps to address loading this fact table.
First, we will need to capture the changed data. In this scenario the source system data will contain a change date we can use to find all of the records updated since the last successful data warehouse loading process was started. A simple select, looking for records where the source record change date is greater than the last successful run start date will allow us to retrieve all of the records necessary to successfully meet the requirements. Like dimensional data, we load this data into a source landing table so that we do not have to go back and request the data multiple times from the source system. This select may have some records we already processed and that is ok. We will will filter out any duplicate data during our load process in a later step.
Next, we transform this landed source data into the staging table seen below. As you can see, this staging fact table contains a data hash column, just like the one we use in our loading of dimensional tables (see Updating Type II Slowly Changing Dimensions post). This data has column will be used to keep us from loading duplicate data and artificially making our fact table larger than it needs to be.
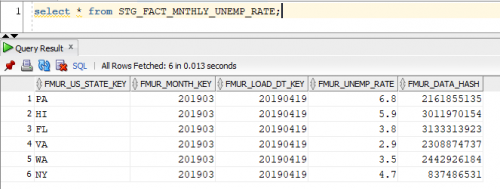
Now that we have data in our staging table, we will go through the same process we did in dimensional modeling. We will compare the key values minus the load date key, which is in the model for record uniqueness, and hash column from staging fact against that of the DW fact. If the key values of a record are in the DW fact and the staging fact, but their data hashes are different then we need to update the active monthly record flag to 0 in the DW fact. Remember you must always do your soft delete’s first.
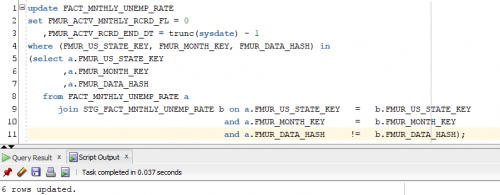
The final step will be the insertion of the staging records whose key values and hash column for active monthly records are different.
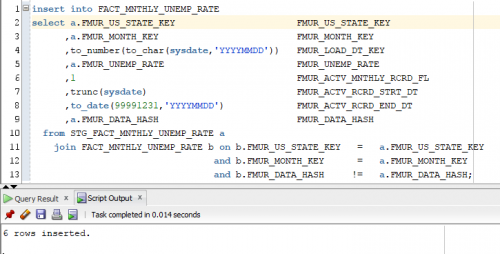
Now, let’s check our work to ensure accuracy. We should now see 6 inactive records and 6 newly inserted replacement transactions for these monthly records.
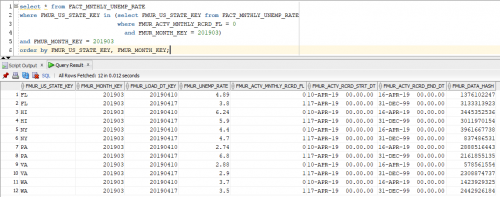
Following this process will ensure that your fact table grows only when actual changes are detected, preventing you from loading all records every day while also eliminating the possibility of duplicate records in the fact table.
