Configuration Management of Microservices using Spring Cloud Technology
It’s a well-known best practice to separate application configurations from the code in the software engineering industry. Today, we will discuss how you can externalize and centralize the configuration of Microservice using Spring Cloud technology.
Design Challenge
According to the Scale Cube, a Microservice System consists of functionally decomposed services. Unlike a monolithic application, each service has a single functional responsibility and gets deployed independently. Imagine this; you end up with hundreds of independent services you need to deploy to multiple environments with different configurations and update them frequently. Furthermore, suppose you have to manage them in a conventional way, such as having property files in one of the source code folders, updating the values in the files, and restarting them every time. In that case, it will quickly become an unsustainable practice.
Solution
It would be best to use the Externalized Configuration design pattern to simplify configuration management. There are two approaches to implementing the design pattern: a Push model and a Pull model.
In the Push model, the user supplies the configuration from the environment or configuration file to each service instance. In the Pull model, each service instance retrieves property values from a configuration server.
The Push model has two significant limitations. First, you must restart after reconfiguring. Secondly, you must manage multiple configuration properties in numerous places, and these make the model unsustainable when you have many microservice instances.
On the other hand, in the Pull model, a centralized configuration server is set up with a configuration repository, which can be a database, Git, a file system, etc. Each service instance retrieves configuration property values from a centralized configuration server at startup. Then, the services periodically poll so that they can reconfigure with new values when the property values get updated in the repository.
The Pull Model Implementation
Using the Spring Cloud framework, you can implement the Pull model in four steps.
- Set up a config server.
- Add two dependencies in pom.xml and configure a client service to connect to the config server.
- Add @RefreshScope annotation in the client service.
- Send the client an HTTP POST call for actuator/refresh.
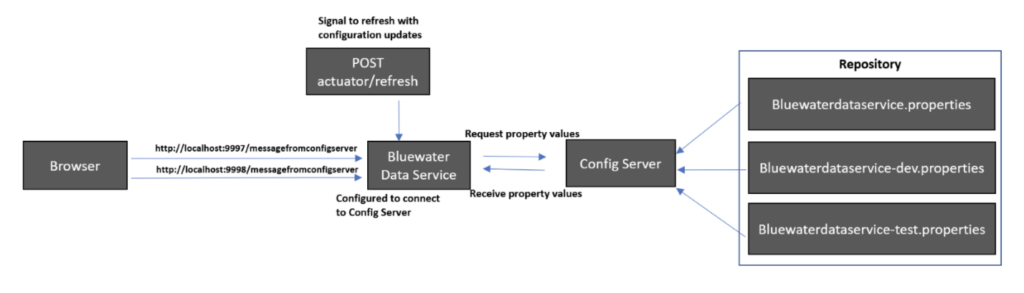
Before going through the steps, I would like to show the architecture of the example that shows each step more clearly. There are four main components in the architecture. The Bluewater Data Service is a client for Spring Cloud Config Server. The config server has all properties of the client service and provides configuration information according to a requested profile. The client service will get configured by dynamic configuration triggered by the HTTP POST to Spring Actuator. You will see a different message back in a web browser depending on whether the client service gets configured with the default or the dev profile.
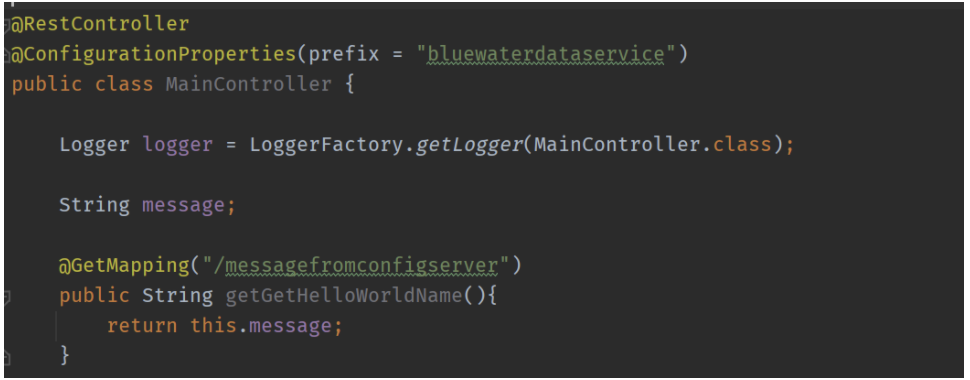
 The figure below shows how a REST controller gets defined with the GET method, /messagefromconfigserver, which returns a value from bluewaterdataservice.message property.
The figure below shows how a REST controller gets defined with the GET method, /messagefromconfigserver, which returns a value from bluewaterdataservice.message property.
Let’s walk through each step in more detail.
Step #1 – Visit Spring Initializr and select two dependencies: Config Server and Spring Boot Actuator, as shown below.
Once you download the pre-built package by clicking GENERATE button, you need to add an annotation @EnableConfigServer, as shown below.

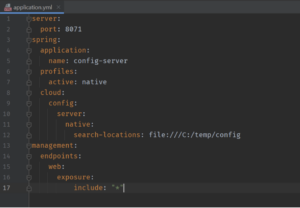
And you need to set up application.yml for the config server, as shown in the figure below. Two key properties are spring.cloud.config.server.native.search-locations for your configuration file location and management.endpoints.web.exposure.include to make the actuator endpoints available. You can see that the search-locations property is specified with a local directory path since the example application uses the file system as a repository. However, Spring Cloud Config Server supports other options, such as Git and HashiCorp Vault.
There are three property files in C:/temp/config directory, and the location is outside the Bluewater Data Service code. The file names follow the Spring naming convention to specify a profile. Because the example uses the file system-based config server, the profile configured in application.yml is native. The config server will pick up Bluewaterdataservice.properties for the native profile configuration.
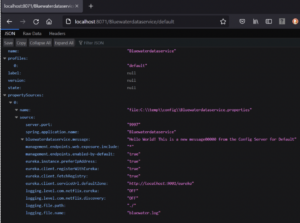
Now, you can build and run the config server by executing java –jar or mvn spring-boot:run command. Once the config service is up and running, you can see the configuration information for a profile by sending a request with a URL as shown in the figure below, which is <config server host name>:<config server port>/<service name>/<profile>.
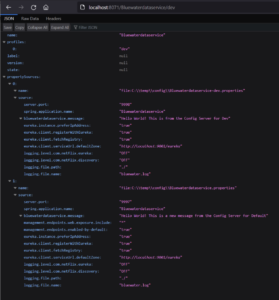
When you request the dev profile, the config server fetches different property values from the repository. This is because the native profile is a default one that will always get used if a property for the dev profile is missing.
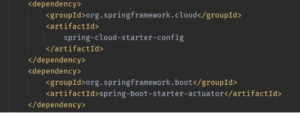
Step #2 – Add the two dependencies, spring-cloud-starter-config and spring-boot-starter-actuator, to pom.xml in your service and configure your service for the config server as shown below. You don’t need anything else in the property file unless you need any values available regardless of the config server state.
The figures below show how the bluewaterdataservice.message and the server.port change depending on spring.profiles.active property in the application.yml of Bluewater Data Service.
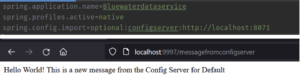
Step #3 – This step is for dynamic configuration. Using the dynamic configuration, you won’t have to restart your services whenever you change the property values. All you have to do is to add @RefreshScope. It will apply new changes when an HTTP POST call gets made for Spring Actuator in the Bluewater Data Service.
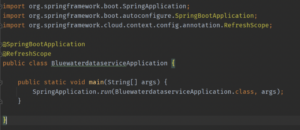
Step #4 – I changed the bluewaterdataservice.message without restarting the config server or the client service, as shown below.
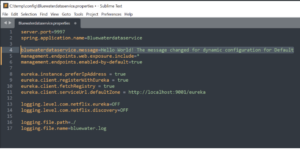
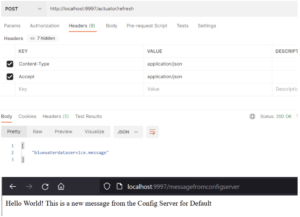
Using Postman, I sent the HTTP POST call to the client service and refreshed the browser. The new message appeared correctly in the browser.
Conclusion
Spring Cloud Config Server helps to implement more scalable configuration management for microservices. Not only can you centralize and externalize the configuration, but also you can apply new changes dynamically without restarting services.
