Why Named Entity Recognition (NER) Customization Matters
From Unstructured Text to Knowledge Graph: Why Named Entity Recognition (NER) Customization Matters

The ability to extract information into a structured useable format is of great interest across many domains, especially since 80% of all data is unstructured. The need for structured information drives opportunities for advanced analytics and modeling.
In this blog, our use case aims to characterize military equipment from open-source text, connecting equipment to entities such as military organizations and manufacturers. Our outcome will be a graph database that contains transformed unstructured text of detected and classified custom-named entities. My primary tools of choice are spaCy and Prodigy. SpaCy is an open-source Python NLP library, and Prodigy is an annotation tool that provides easy integration with SpaCy, allowing the user to build and evaluate machine learning models.
I will be focusing on Named Entity Recognition (NER), as well as token2vec. Token2vec is a method in spaCy’s pipeline that creates a vector representation of the tokens. The xx2vec nomenclature was first used for Google’s word2vec embeddings. Word2Vec representations provide similar vector embeddings for semantically similar words while token2vec embeddings provide representative vectors based on spans of text. Token2vec is built concurrently during the NER model creation process. The NER model is used to detect key information in text and classify that information into categories. NER is a critical step in the NLP pipeline as errors in NER propagate to the relationship extraction step and will provide an overall poor finalized graph if not done properly.
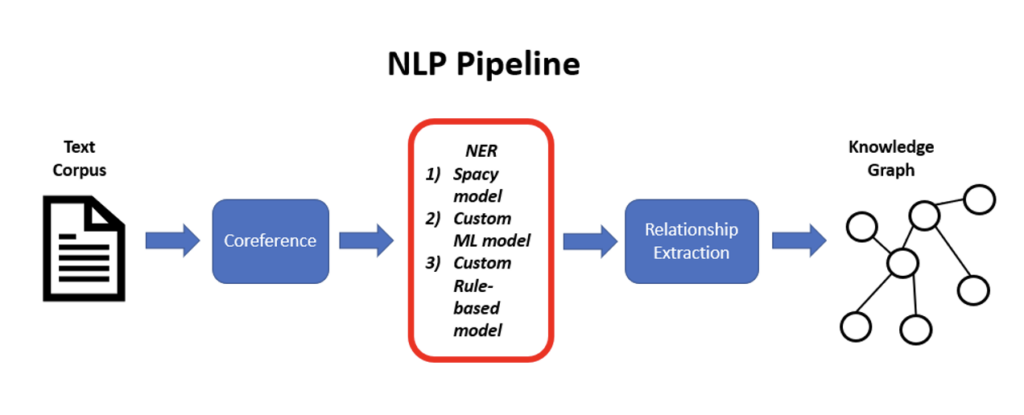 Figure 1: NLP pipeline for text to graph transform
Figure 1: NLP pipeline for text to graph transform
Why Customize?
Although out-of-the-box models perform well with common terms, they will not classify more specific categories well, if at all. Additionally, dictionary-based models (where entities are tagged based on a known vocabulary) and regular expression models (where entities are based on established text patterns) will only find known items – making customized machine learning models a necessity for finding new entities of interest.
To further explore why out-of-the-box models don’t work in all cases, we can observe the vector similarity between two equipment terms using the popular spaCy model en_core_web_lg. What we discover is when comparing two pieces of military equipment (Y-9 and Mi-17) via their vector representations, we get a similarity score of 0 [see Figure 2]. This isn’t surprising given that the equipment entity class is unique, and therefore its representation does not exist in a general model [see Figure 3].
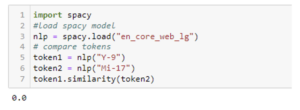
Figure 2: Token Vector Similarity Score using out-of-the-box model
Additionally, we can check to see if the out-of-the-box NER model contains a vector representation by running the following commands:
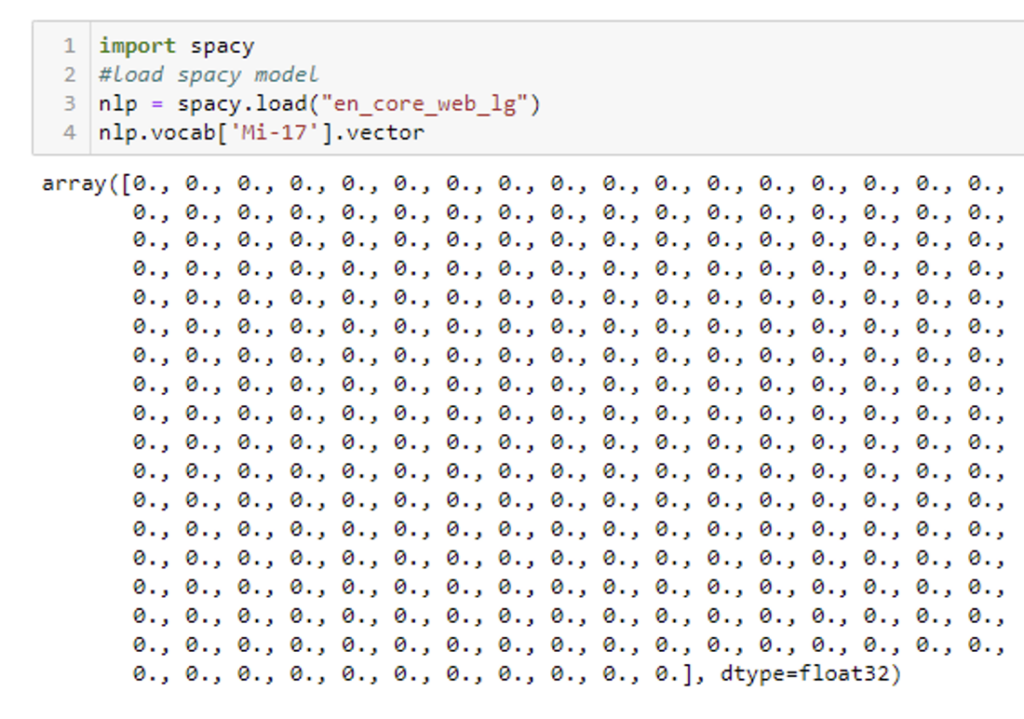
Figure 3: Vectorization of equipment instance using out-of-the-box model
The model doesn’t know how to represent Mi-17, and so it returns a vector of all zeros. If we instead look at our custom-trained model, we find that the vector representation of the equipment Y-9 and MI-17 are similar (scores range from zero to one with one being a perfect match):
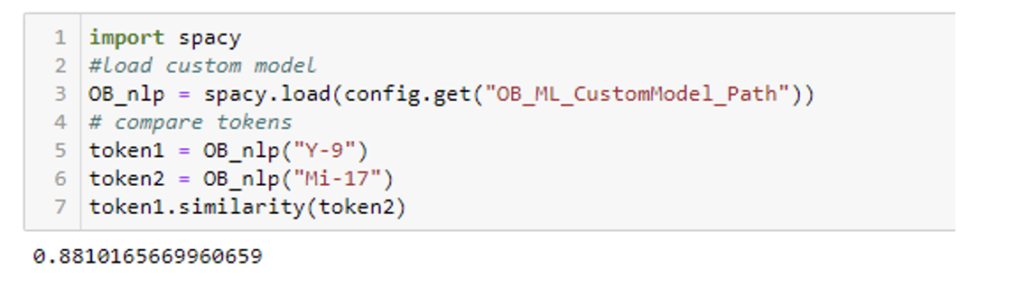
Figure 4: Token Vector Similarity Score using updated custom ML model
How We Built Our Custom Model:
Our customized NER model was built using approximately 370 open-source military articles. The number of tags per entity class was 1,033 (military organization), 661 (equipment), and 308 (role). Once data has been annotated, we use Prodigy’s built-in training functionality to fine-tune pre-trained models via transfer learning.
The initial F-score results (Figure 5) for the three custom-trained entities are promising and show superior scores based on their representation in the text.

Figure 5: F-scores across 3 unique categories
Further Model Improvement:
There are numerous ways to improve these model metric scores. First, annotators can complete several passes on the annotated dataset and further tune annotations for consistency. The user can also observe the predicted vs annotated tags to get a better feel for how consistent they are with their tag definitions and whether their annotation guidelines need to be fine-tuned. Training the spaCy pipeline initialized with BERT pre-trained transformer weights could also improve performance.
Additionally, one might tag more data to provide a better representation of each class. Prior to completing this task, it’s recommended to observe the training curve to determine whether additional data will help. The training curve, as observed in Figure 6, calculates F-score improvements as data is added to the training set. As can be seen in our model’s training curve, accuracy continues to improve as additional data is added. Therefore, tagging additional data will improve our model.
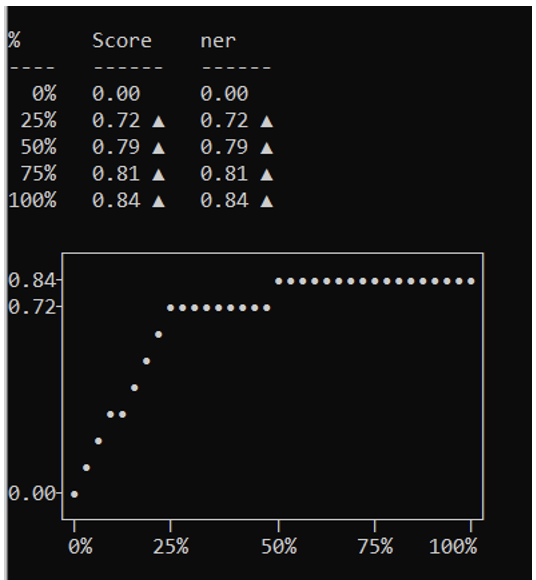
Figure 6: Training curve: Performance of NER model based on F-score vs. amount of training data
About the Author
Kim Riley is a Principal Data Scientist at BigBear.ai. Kim has more than 15 years of experience across a range of analytical tasks including data manipulation, signal processing, computer vision, natural language processing and forecasting.
