Serverless Analysis of data in Amazon S3 using Amazon Athena through KNIME
This blog describes how to perform Serverless Analysis of data in Amazon S3 using Amazon Athena through KNIME. Let’s start with quick introduction about Amazon Athena.
What is Athena?
Athena is serverless query service for querying data in S3 using standard SQL, with no infrastructure to manage. It supports ANSI SQL queries with support for joins, JSON and window functions.
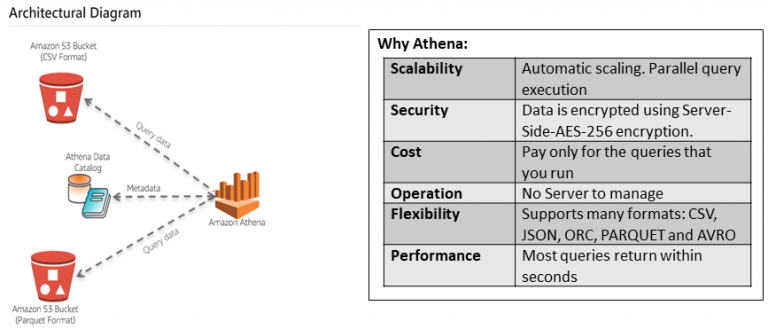
Figure 1 – Athena Architecture
How to connect Athena and execute SQL from KNIME?
KNIME can interface with Athena using the following nodes.
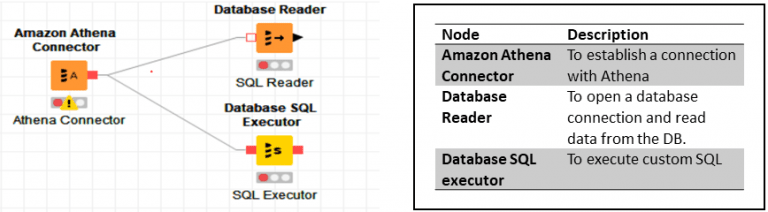
Figure 2 – KNIME Nodes
How to do Analysis of data in S3 using Athena trough KNIME?
A traditional approach is to download the entire files from S3 to KNIME using a Node such as the Parquet Reader. This approach works fine if the file is relatively manageable in size. But if you have large files in S3, then this download approach will consume lots of time and local memory and processing will be slow because of data volume. Athena can help with these issues. Since Athena supports SQL processing on top of S3, all heavy lift data processing such as joins, filters, and group-bys can be done using Athena (inside a Database Reader Node) and only processed result sets are downloaded locally into the KNIME workflow. This design pattern works well for large Data Analysis use cases. Here are some specific examples shown with and without Athena in KNIME.
Use Case 1: Querying partitioned data from S3:
This first example demonstrates how an Athena query can reduce the amount of network I/O from file download options. The better approach is to use a Database Reader node which connects to Athena and performs SQL to get only required partition or subset of data using a WHERE clause.
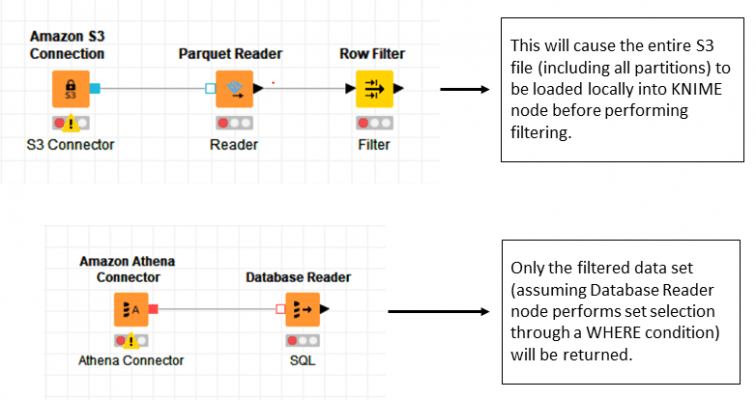
Figure 3 – Querying S3
Use Case 2: Joining and grouping S3 data:
Instead of downloading, joining and grouping through KNIME nodes, it is very efficient to do joins and groupings using Athena. This will typically result in better performance and memory consumption. Since Athena complies with ANSI SQL, all flavors of join such as inner, left outer and right outer are possible.
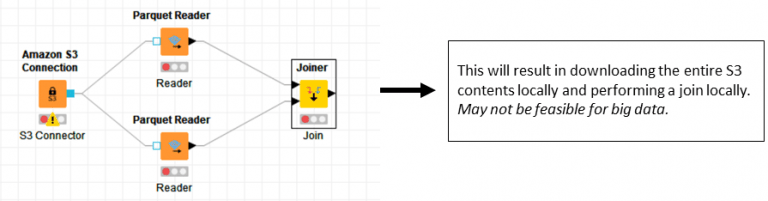
Figure 4 – Joining & Grouping S3 Data
Use Case 3: Processing, conversion and Transformation of S3 data:
Let’s say you want to process S3 data and perform operations such as data cleaning, conversion, de-duping, deriving new columns using existing columns, etc. All this data processing could be done in Athena without ever even transferring the result set locally until other KNIME nodes are needed.
In this scenario, each Database SQL Executor node performs an Athena CTAS (Create Table As Select) query. Use this CTAS design pattern to create a new table from the result of a SELECT statement from another query. Athena stores data files created by CTAS statement in a specified location in Amazon S3. Note that each CTAS will result in creating new file in S3. Downstream KNIME database nodes can then interact with the newly created S3 data as an Athena table.
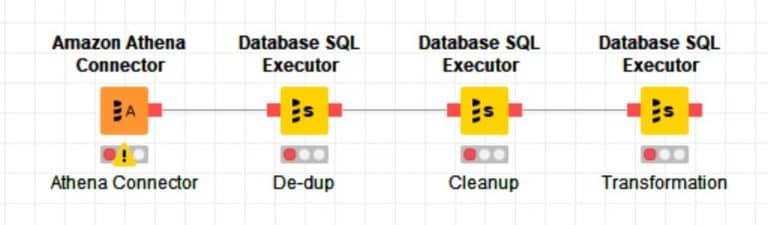
Figure 5 – Processing S3 Data
Use Case 4: Changing format of S3 data:
If you have S3 files in CSV and want to convert them into Parquet format, it could be achieved through Athena CTAS query. For example, if CSV_TABLE is the external table pointing to an S3 CSV file stored then the following CTAS query will convert into Parquet.
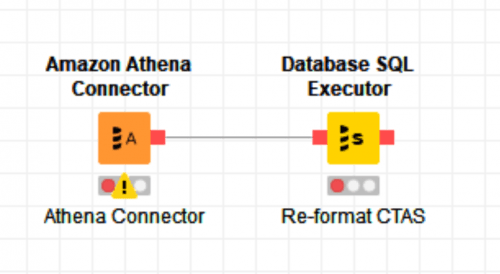
Figure 6 – Changing S3 Format
CREATE EXTERNAL TABLE PARQUET_TABLE
WITH
(
Format=’PARQUET’,
External_location = ‘s3://bucket-name/key-name/’
)
AS
SELECT * from CSV_TABLE;
Use Case 5: Re-partitioning Dataset in S3
Athena is priced by the amount of data scanned per query and uses partitioning to reduce the data that requires scanning when Where clauses are specified. Hence, smartly partitioning data helps control costs. In order to repartition S3 data, we need to create new S3 files for each new partition. This can be done using an Athena CTAS query. By using the Athena CTAS query we can eliminate entire data downloading locally while creating partitions as needed.
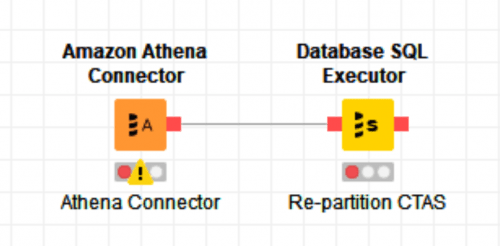
Figure 7 – Re-partitioning S3
CREATE EXTERNAL TABLE REPARTITION_TABLE
WITH
(
Format=’PARQUET’
External_location = ‘s3://bucket-name/key-name/’,
Partition_by=ARRAY[‘year’,’month’]
)
AS
SELECT * from PARTITION_TABLE;
