Automatic PDF Processing with UiPath
Manual data entry from PDF forms is a common business process. While there are ways to use Adobe technology to automate data collection through fillable PDF forms, many people employ a “look left and type right” process to enter important data into business systems. This blog focuses on using UiPath to build automation capable of processing a series of PDF forms and create a CSV file with the required outputs. This process outline culminates at a step ready for secondary actions, including emailing results to a specified recipient, uploading to online file storage, or directly updating a database with the new data. Additionally, this blog features a special focus of some of the more complex components of processing a PDF (variable names in camelCase).
Fillable PDF forms are a step above less-structured data collection efforts, such as email. Each specific entity required for collection exists as a separate PDF text box, drop down list, or check box. As seen at right, Image 1 is the example fillable PDF used for this automation. Separate blanks exist for the entry of name, address, postcode, city, and more. Country, gender, and favorite color exist as dropdown list items (and serve to restrict what the user may enter). Driving license status and language capabilities are handled through check boxes. Forms with this type of structure (as opposed to free text) are easily reimagined into a series of data columns. Strings for most of the fields, integers for height and postcode, Boolean for the driver’s license, and an array for the languages. A running list of development steps and helpful code notes accompany the outline below.
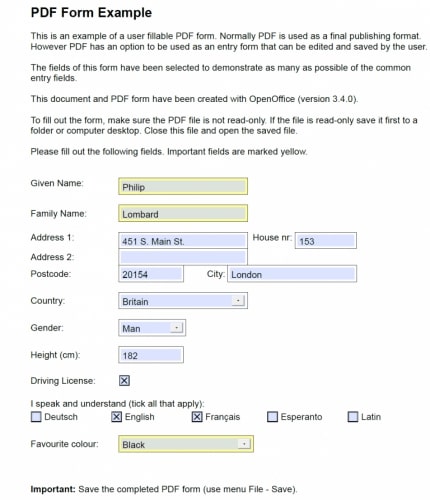
Image 1 – Example PDF

Image 2 – Example Data Table
Initial Setup and a For Each Loop
First, the automation requires some initialization to the location of the forms. Create a list of file paths to each form. Initialize a Data Table object and then build a table that corresponds to the form (see image 2). The above image displays a possible interpretation of the PDF form as a data structure. A randomly generated unique ID is included for database clarity. Employ a ForEach loop activity to iterate across the list of files provided in the String[] variable. The top of this loop is a good place to initialize a new Data Row object and ensure no data leaks across loop iterations.
Initialize variables, setup ForEach loop, create Data Table and Data Row objects
- String[] variable to the directory: Directory.GetFiles(“C:UiPathProcessFormForms”, “*.pdf”)
- Initialize Data Table: New System.Data.DataTable
- Initialize a Data Row structure: form_data.NewRow()
Extract Plain Text
Now that we have the initial looping concept, we need a way to extract PDF text. There are no native PDF activities to UiPath, so access the Manage Package menu on the design tab. Select “All Packages” or “Official” and type in PDF (see image 3). There are a great number of available packages featuring PDF tools, but for the purposes of this project I chose the official UiPath PDF Activities package. This may only work for UiPath Studio v2018.4.4 / v2019.2 and above. Once installed, you now have the “Read PDF Text” activity available for use.
The Read PDF activity accepts a file path, an optional range of pages and returns a string value of all contained text. To determine what part(s) of the PDF to process, first ensure you are not tricked by unusual encoding or odd text formatting. Examine the text output and look for “Split Points”: one or more places in a PDF where you can split this text string and focus on the desired data. To help find these locations, draw a line immediately above and below the part(s) of the PDF that are required for database entry. Look at how you can programmatically identify these areas to the automation. Our example form is relatively simple and splits easily at the starred lines of image 4.
An underscore character is the delimiting character in this example, but you must ensure there are no stray underscore characters elsewhere that would interfere with the splitting. After inserting underscores, an assign activity performs the splitting action and creates an array of three Strings (index 0, 1 & 2). The desired string value exists at index 1 and consists of a giant paragraph of all form fields. This string value is split vertically on linebreak characters to return a new string array to the automation. This array comprises the form entry section of our PDF, with each form field line as one index within the array. This step may require some additional text modification to produce the desired result.
Image 3 – Manage Packages

Image 4 – Delimiting Points
Use Assign activities to insert a delimiter, split on that character, and then split on linebreaks
- Insert Delimiter: fileText.Replace(“Given Name”,”_Given Name” ).Replace(“Important:”,”_Important:”)
- Split PDF Text on delimiter: fileText.Split(“_”c)(1)
- Split value on NewLine: fileText.Split({Environment.NewLine}, StringSplitOptions.RemoveEmptyEntries)
Review Current Data and Adding Values to the Data Row
Image 1 – Example PDF
The Multiple Assign activity is an excellent choice here to assign many values to our Data Row and stay organized. Before simply mapping the array created by the vertical splitting, compare each value with the PDF (reposted for convenience).
At first glance, the general pattern of each array value is a complete scrape of the entire line: text field title and value (for example, “Family Name: Lombard”). We can discard the title, and thankfully every field title in this PDF ends with a colon character (split action at right). Splitting neatly on the colon fixes many of these values, but different PDF structures may require extra work to produce a clean value.
Our data table has thirteen columns of expected data. Using the split action above we produced seven clean values, failing to properly map the multi-field lines (Address #1 and Postcode) and the checkbox lines (Driver’s License and Languages). At right are examples of creating our random integer, combining Address #1 and House Number, and splitting Postcode and City.
We now have eleven values ready to map from PDF to the Data Row. There is an issue with checkboxes and the Read PDF Text activity, explored in the next step.
Map values to Data Table
- Split initial value: textSplit(0).Split(“:”c)(1).Trim
- Create Random: New Random().Next( 10000, 99999 )
- Combine Address1 & House Number: textSplit(2).Split(“:”c)(1).Replace(“House nr”,””) + “#” + textSplit(2).Split(“:”c)(2).Trim
- Produce PostCode: textSplit(4).Split(“:”c)(1).Replace(“City”,””).Trim
- Produce City: textSplit(4).Split(“:”c)(2).Trim
Extract Text with OCR
When the checkbox lines of data are processed into our array the title is scraped but the box is not properly evaluated. This likely depends on the encoding and PDF format, so plan on customizing this code for each different PDF.
Since checkboxes are not properly evaluated via this Read PDF action, we look for another activity to better handle form controls such as checkboxes. Enter Read PDF with OCR, a way to capture at least some data from these checkboxes. Place a Read PDF with OCR activity next in the ForEach loop and write this value out to console for examination. In this instance, instead of a clearly identifiable “X” for an affirmative checkbox result, we get an OCR interpretation.
In my test runs the OCR activity yielded a variety of results for unchecked boxes: “EI”, “[I”, “[:I” and a few others. This is discouraging until noticing that checked boxes result in a nullstring value. Now we can setup some code to check each value for length. Equal length = Positive result, longer = negative. Update the DataRow with this value.
The “Driving License:” title is 16 characters long; any value of length greater than that is a negative result. Check the length of this value in an If statement and record the answer appropriately. The language line is slightly more complex and requires extra work.
There are many ways to work this out, but the method I employed was to create a default language object to compare value for value against our array. Next, we need delimiters on our language string from the PDF values (accomplished via the complex replacement operation at right). Split that string on the underscores to make a new array. I used a list collection object to add each language identified as a checked positive. In a ForEach loop, compare the length of each PDF language value against the length of the default language value. If the values are of equal length, add it to the list collection. After the ForEach loop, convert the collection to an array and add that to the language column of the DataRow. With all values of the DataRow properly initialized we can add this DataRow to the Data Table before the loop repeats.
Image 5 displays the final output of this Data Table.
Evaluate results from OCR scrape into useable values
- Split out just the Checkbox lines: pdfStr.Replace(“Driving License”,”_Driving License”).Replace(“Favourite colour”,”_Favourite colour”)
- Default Language Array: { “Deutsch”, “English”, “Francais”, “Esperanto”, “Latin” }
- Add Delimiters to PDF Language String: pdfSplit(2).Replace( “Deutsch”,”Deutsch_”).Replace(” English”,”English_”).Replace(” Francais”,”Francais_”).Replace(” Esperanto”,”Esperanto_”).Replace(” Latin”,”Latin_”)

Image 5 – Output CSV
As a conclusion to this lengthy outline of a complex (yet realistic) business process, there are a few takeaways. Obviously, there is great variability to this type of process based on the structure of PDF and the internal formatting. Writing these strings out to the console and working the problem line by line is a good practice. Eventually, comparing the PDF with a blank version of the form yields enough comparison to convert even tricky checkboxes into structured data. A non-exhaustive list of best practice lessons:
- The official UiPath PDF activities package features multiple activities to assist with PDF processing
- The Read PDF Text activity effectively scrapes all text and most form controls (except for checkboxes)
- Careful employment of delimiters or already present splitting characters is vital
- The fillable fields in most PDF Forms are separated vertically by line breaks, enabling easy conversion into an array of values
- Multi-field lines require extra splitting or combining as appropriate
- The Read PDF OCR activity is likely required to evaluate checkboxes; requiring careful evaluation to identify consistent outputs to interpret into proper data
- Due to the time to build an effective UiPath automation, balance the benefits of use and durability of the PDF forms. Consider working to standardize PDF forms within a business process prior to working on more complex automation
