Cloud Data Hub / Data Science Architecture
Have you ever imagined a world where transactional systems were able to focus solely on the tasks they were built to complete? Have you ever wanted to synchronize data between applications using the application-provided APIs and not via custom synchronization scripts that reduce the performance of the transactional system? Have you ever needed to extend your enterprise data warehouse to leverage unstructured and semi-structured data? Have you ever wished you could use the processed data from your warehouse as an input to your data science projects? The answer to all of these questions is with a data-centric cloud architecture, “you can!”
Today’s organizations need to take advantage of the scalability, reliability, and flexibility of the cloud. They need to fully leverage all of their structured and unstructured data for a competitive advantage against their competitors. And this “data exploitation” needs to be done with minimal impact to the transactional applications and without users losing access or fidelity in their existing analytics and reports. In this post, I will show you how to create a data-centric Data Hub / Data Science architecture that will revolutionize your organization, unlocking the full potential of your data.
Below is the high-level design for the cloud Data Hub/Data Science architecture. Individual pieces of this architecture have been around for years, but the cloud has made this idea a reality.
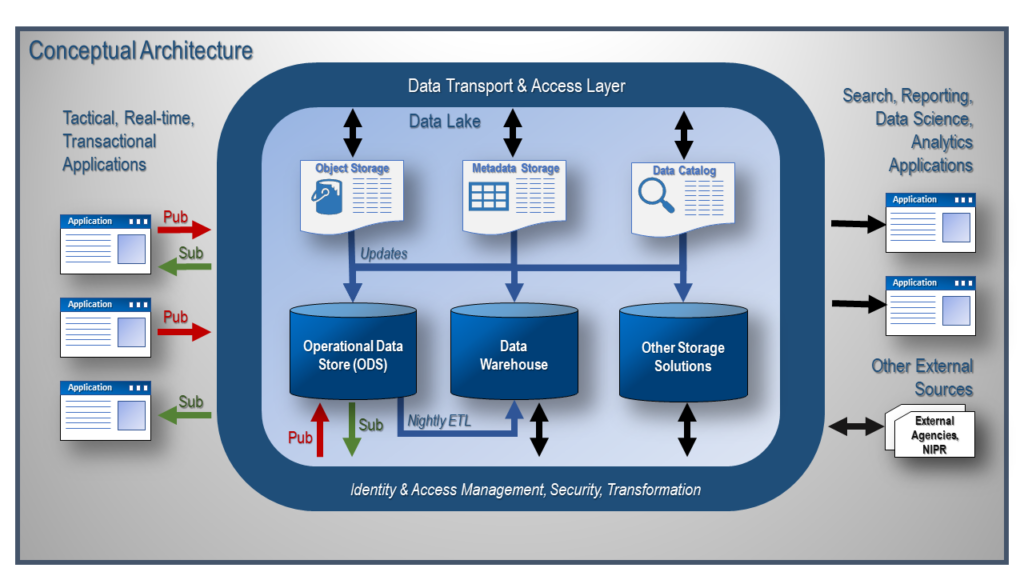
Figure 1. Cloud Data Hub / Data Science Architecture.
On the left side of this conceptual architecture diagram, we have our transactional systems. We set these applications up in such a way that they can send and receive data to and from other applications via the Operational Data Store. The Operational Data Store is multifunctional in this architecture. First, it serves as a data hub for the transactional systems. The green and red arrows show how the transactional systems will interface with the ODS. Applications can publish their changes to the data hub via secure APIs, but this will incur extra overhead (CPU & memory usage) on the application. I recommend using a low-latency, heterogeneous database change data capture (CDC) technology that will retrieve the modified data and replicate it to the ODS in near real-time with minimal resource usage.
Once the data has been inserted, updated, or deleted in the transactional system and replicated to the ODS landing area, the ODS then retrieves the transaction and applies the modification to the database. This change then kicks off a process that will push the changed data from the ODS (data hub) to each application that subscribes to receive that change.
Today, in most organizations, the synchronization of application data is done once a day. It consists of a complex process of data feeds and non-standardized change data capture (CDC) processes. Synchronization via files (CSV, XML, JSON, etc.) is, at best controlled chaos. It is a process that is wrought with potential errors and sub-optimal usage of application resources.
In Figure 2, you will see the complexity that many of you may have experienced or are still experiencing daily caused by application and data integration via files/feeds.
In some cases, the applications are integrated via code, sharing functionality, to make the combined applications act as a single system. This is an expensive solution to solve the missing functionality challenges of an application. The direct costs are the initial amount of resources (time, money, people) needed to integrate these applications. The indirect costs occur when a new feature is added to one of the applications. Because the applications are tightly integrated a team of people must be rallied (taken away from scheduled projects) to perform the upgrade and/or fix the issues triggered by the change. The delays produced by the tightly coupled applications can have a significant impact on the profit and/or productivity of the company due to scheduled work not being completed when planned.
Another common way to integrate the applications is via files. In this scenario, each of the applications creates one or more files to synchronize data with another application. Sometimes the files are completely redundant or have an additional field, but are sent to separate applications. The processing time wasted on this solution pales in comparison to the cost, in both real dollars and opportunity cost, of creating and maintaining this system. The issues that arise often go unnoticed for days, weeks or even longer. I have seen instances where data structures were modified to add new information to the source system, causing a change in the data model and thus the file structure. With a new, unannounced file change, the import process on the downstream application no longer functioned. I have also seen instances where the receiving system was never informed of newly available data and added the redundant, customized functionality into their application.
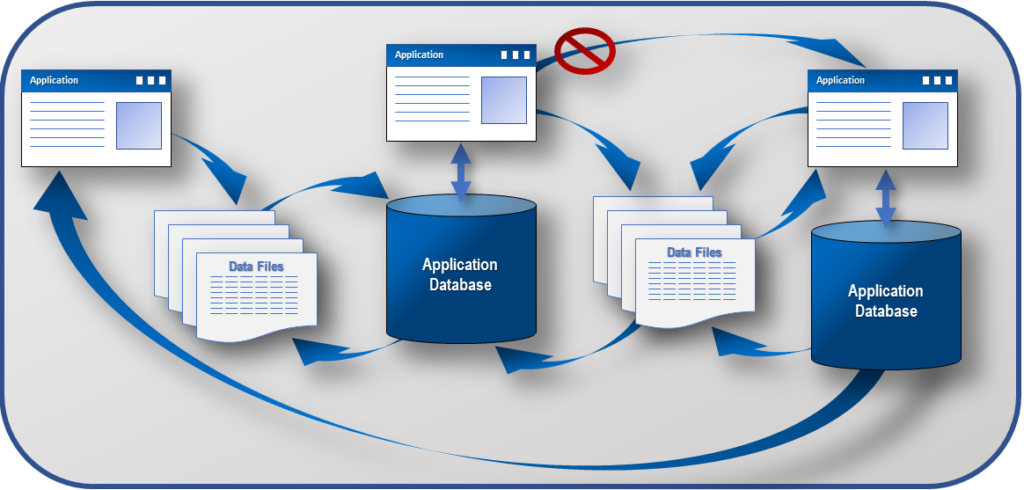
Figure 2. Application Integration and Synchronization via Data Files
Let’s walk through the same scenario of this pub/sub data hub update. I like to use the processes from an old employer, a membership society that has a journal publication division, and a meetings/conferences division. This company has members who may also be authors of journal articles and attendees at upcoming events. Looking at the three systems on the left side of Figure 1, imagine the top application is a membership system, the middle application is an article submission system, and the bottom application is a conference management system. When the membership system generates a change, for example, to a member’s email address, the update propagates to the ODS, where the most up-to-date information about the member will be stored for enterprise operational reporting purposes. This change to the ODS data will cause a synchronization process to be initiated on the ODS. This process will push the member’s updated email address to all applications that subscribe to this change from the membership system. In the example, the conference management system subscribes to the change, but the article submission system does not. So, the member’s updated email address will be sent to the conference management using that application’s native API. Now, I have both systems in synch in near-real-time. If the member jumps over to the conference management application, he/she will see that their email address has been updated, providing the customer with the feel of a single integrated system instead of a “best of breed” solution.
Now that the transactional data is centralized, I have the ability to off-load my enterprise reports from the application to the ODS. Long-running, CPU and memory intensive reports can now be processed on the dynamically scalable infrastructure of the ODS. The applications can focus on the tasks for which they were created, capturing transactions.
If I want to upgrade the membership application, I can. The impact here is minimal. All one needs to do is to update any changed API to ensure it works with the ODS. You will also need to ensure that new and deleted fields are handled correctly in the ODS. That is it! No impact on my downstream applications. They still received the data that they have always have, no changes necessary.
As you can see, this solution also allows the applications to be totally independent and easily replaceable should the business needs change, and new applications are required to meet the organizational objectives. This architecture also removes the need for the creation of multiple, specialized feeds for each application. I have been there, trying to make sense of this spaghetti bowl of feeds. The who gets what, how do you process the data, and what happens when something goes awry questions can make you go crazy trying to untangle the mess and find the source of the issue.
In my next post, I will focus on the data lake and how the enterprise can fully leverage all of the data in the lake for competitive advantage.

