Cloud Data Hub / Data Science Architecture – The Data Lake
In my previous post about the Cloud Data Hub / Data Science Architecture, I focused on the interface between the Operational Data Store (ODS) and the transactional applications supporting the business. In this post, I will be discussing the data lake and the components inside of the lake.
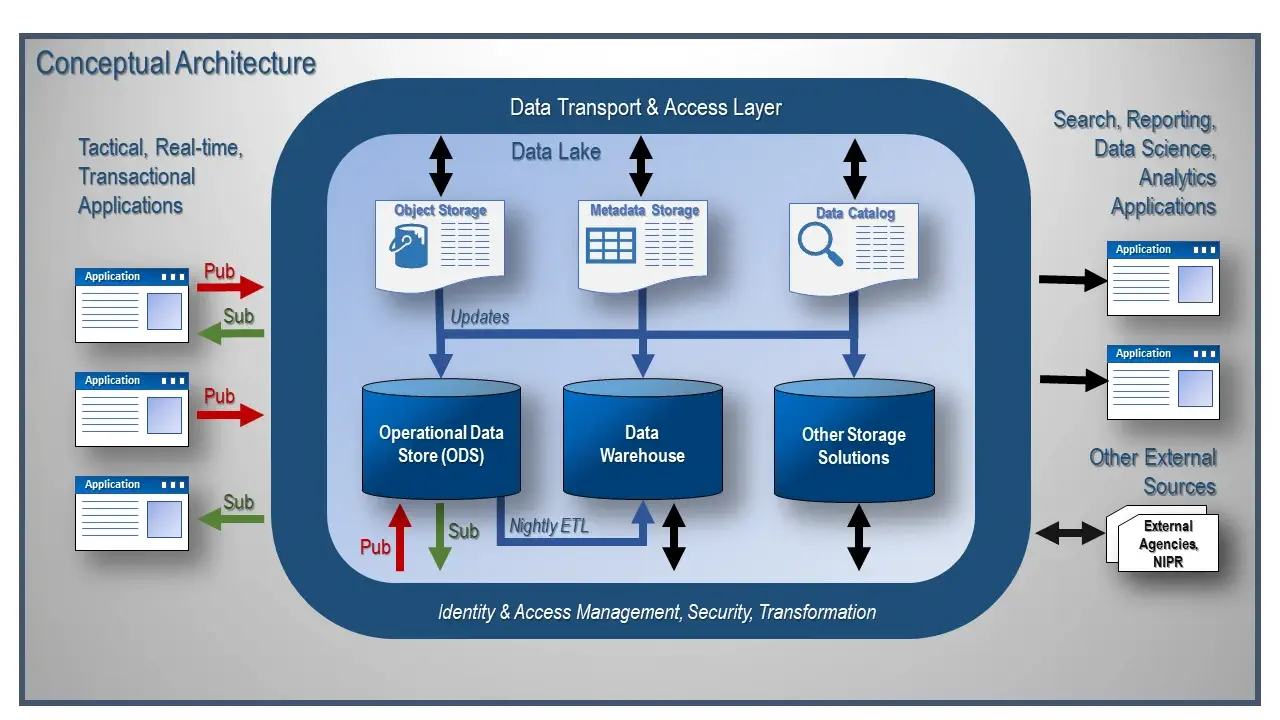
Looking at Figure 1 above, the data lake is made up of more than just an object data store, a data catalog, and metadata storage. This architecture includes the ODS and the Data Warehouse (DW), as well as other storage solutions like graph databases. Many people have asked me why I have included processed data in my data lake. My response is, why not?
Let’s dive into the benefits this architecture provides. Let’s start by looking at using the raw object store as an extension of the data warehouse. I have, on occasion, found interesting information in the object-store. This information was later deemed to be integral to the business and needed to be reported upon. We then captured and processed the raw data sourced in the object data store and stored this new information in the data warehouse to be used in the reporting process.
As you can see, this object data store can be used as a data source to the Data Warehouse. There are also occasions when the data warehouse needs to provide supporting information, supplying additional detail and support for KPIs reported to the user. As you can see, these are excellent ways to use the object store as an extension to the data warehouse.
Similarly, the ODS can also use the object-store. For example, you could use the ODS to provide consistent images or synchronize documents/pieces of documents between transactional applications. This data-centric architecture, with the ability to sync data from different applications, creates a flexible, best of breed solution for your transactional system tier. You can now treat your transactional systems as commodity applications that can be easily swapped out as technology and business needs evolve.
Next, we have instances where Data Scientists store intermediary data so that it can be used for the validation or additional processing steps of the model. Sometimes this information provides critical insights into the business and is therefore valuable beyond the intermediary step processing of the model. It could and should be stored for reporting. This storage solution, for example, maybe a ledger database, a multi-modal database, or another storage solution. This intermediary data could also be reused for future data science workflows and therefore saved when appropriate. Reprocessing of the same data more than once is a suboptimal use of resources and is easily avoidable with the cloud data hub architecture.
Finally, we have the instances where the Data Scientist could use data that has already been processed and is sitting in the data warehouse. There should not be a rule preventing a Data Scientist from using processed data as an input to their project. It is a more efficient use of time, CPU, and memory to leverage data that has already processed rather than reprocessing this data for each model because of some unwritten rule stating you cannot/should not use the data warehouse’s pre-processed data.
Sometimes this lack of use of pre-processed data is due to the Data Scientist not trusting the data, how it was processed, or the timeliness of the data. This can easily be addressed by using the metadata storage and the data catalog. These tools are critical to the success of the architecture. These data structures are kept in sync with the data being processed, the lineage and definition of the data, and the processing done to the data. The clarity provided by metadata storage and the data catalog promotes the reuse of data and the optimal use of resources.
My view of the lake is broad and inclusive. I believe in creating a flexible architecture that fills your toolbelt with as many tools as possible before embarking on your quest. Now that you have many options, you are fully prepared to handle any issue efficiently instead of sacrificing time and treasure because you only have a single tool, the proverbial hammer, available for use.
In my next blog post, I will continue my discussion of this architecture and describe the data access and transport layer.
