Cloud Data Hub / Data Science Architecture – The Data Transport and Access Layer
In my previous post about the Cloud Data Hub / Data Science Architecture, I focused on the data lake. In this post, I will be discussing the data transport and access layer.
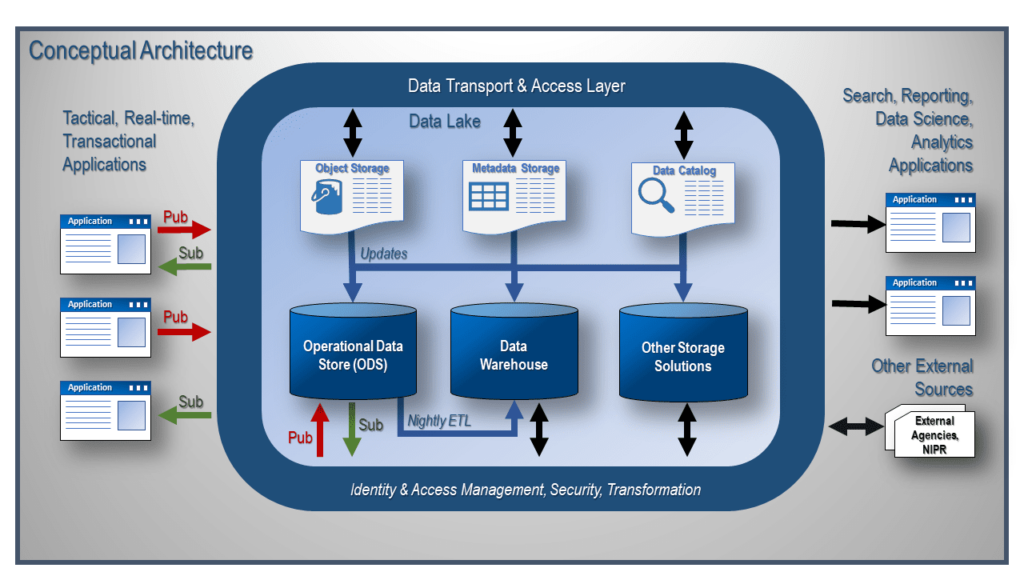
As you can see from Figure 1 above, the data transport and access layer is central to this architecture. These layers of identity and access management, security, and data transformation are the glue that holds the architecture together and keeps the architecture from becoming bound to specific applications that use the data. Let’s take a deep dive into each of these layers and see how they work together to provide a flexible, scalable, data-centric architecture for an enterprise.
Starting on the outside of the data transport and access layer, we see our commodity transactional and reporting applications, which we discussed in detail in the first blog post of this series, Cloud Data Hub / Data Science Architecture. Although the pub/subprocess is executed within the Operational Data Store (ODS), the data movement and data lake security is governed by the data transport and access layer. Reporting, data science, and analytics applications, as well as any external data source, are also subject to this security and transformation layer.
The transport layer defines how the satellite applications will connect with the data lake. This transport layer is implemented via an enterprise service bus (ESB). This ESB allows the applications to be decoupled from each other, leveraging existing APIs where possible, eliminating custom, tightly integrated connections between the systems. This decoupling provides agility for connected systems. Upgrading and replacing applications no longer have a negative impact on time, money, and resources caused by custom code solutions. The ESB also provides a central location to monitor and troubleshoot issues that may arise from time to time. As you can see, this ESB is critical to the successful implementation of this architecture.
Now that we have established a secure connection from the application to the data lake, we need to allow for the authentication and authorization of the application/service to the data lake and vice versa. To do this, we need to implement an identity and access management layer. This layer will provide connections with the least privilege necessary to complete the tasks required. For example, looking at the middle application in Figure 1, we see that it needs to publish the changes from the application to the ODS; therefore, we may create a change data capture process that will push the changed data to the ODS via the ESB. We could also grant access to the ODS to read the DB transaction log from the application database to obtain the modified data. In either case, the data access into or out from the data lake must run through the ESB to ensure the security of the data in the lake.
Not only does the transport and access layer provide enhanced security, but it also can be used to implement auditing and also can be used as a conduit to capturing enhanced provenance and history for all of the data in the data lake. This metadata can be stored in the data catalog as a part of the data lake. The capture and storage of this metadata are critical for today’s public and private sector enterprises. Organizations that capture and manage metadata well will be able to successfully exploit the data in the data lake, allowing these organizations to increase corporate profits or to promote the betterment of society.
The final layer is the transformation layer. The transformation layer is where most of the action takes place. Here is where the brain of the pub/subprocess lives. This application understands when to go and retrieve data from the source systems. It understands what the data is, where it came from, and where it needs to be stored. Once this data has found a home in the ODS, it now looks to see which application has subscribed to receive the changed data. This application finds and executes the appropriate registered API that will insert, update, or delete the data from the transactional system based on whether the data was inserted, updated, or deleted in the ODS.
The transformation layer is also the place where the change data capture processes used to load the data warehouse occur. These ETL programs will use data from the ODS and data from the satellite transactional systems to meet the needs of the data warehouse and reporting applications. Forcing all data access and transformations from external systems to go through these layers ensures the data is secured appropriately, prevents unauthorized access or the execution of rogue transactions, and ensures optimal conversions are done on the data. I see this as a critical architectural decision, especially in environments that deal with sensitive or classified information.
Finally, we have to account for the needs of the data scientists to perform CRUD (Create, Read, Update, and Delete) operations on all of the data available in the data lake. Here we need to include the ability to move the algorithms to the data. Security is done at the data level by creating security rules for what data the algorithm can access while running INSIDE the data lake. This model of data security is critical to ensure the data scientist can fully take advantage of all data contained in the lake.
This post concludes my high-level Cloud Data Hub / Data Science architecture series. I hope that you found this series to be insightful, and I look forward to seeing this architecture become the new standard for Data Warehouses and Data Lakes everywhere. If you have any questions or concerns about this architecture, leave a comment below and start a discussion.

