Comparing CSV Files Using KNIME
I was recently tasked with retrieving a file from a website for use in our anticipatory analysis tool. The file contained 45 years of data. The requirement was to split the file into yearly files in case the start date started to roll forward. The main requirement was only to upload a file to our S3 bucket if the data changed. This changed file would then cause another task to be executed to ingest this new data into our tool, surgically replacing the old data. This process allows us to optimize our ETL workflow and optimally refresh a data store measured in hundreds of gigabytes, keep our data fresh and relevant, and thereby enhance the accuracy of our predictive tool.
At first, I was stumped on how to complete this task and what tool to use. Then I thought about the flexibility of KNIME. I was confident that I could complete this task using KNIME, so I fired up the KNIME IDE and started to design my solution.
Step one, retrieve the data. Retrieving the data was easy. I was given a link that pointed to an Excel file that was updated yearly. I grabbed an Excel reader and put in the link to the file (see Figure 1.).
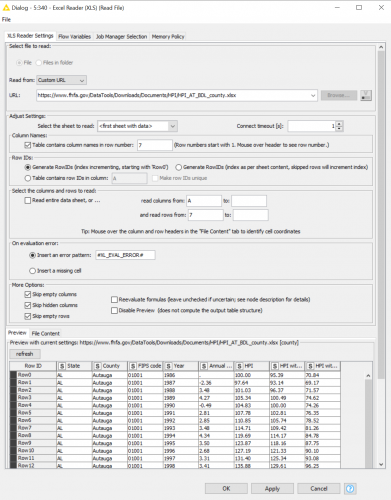
Figure 1
Now that I have the data, I need to put it somewhere, so I use the local file system to land the data using the KNIME variable (Figure 2.).
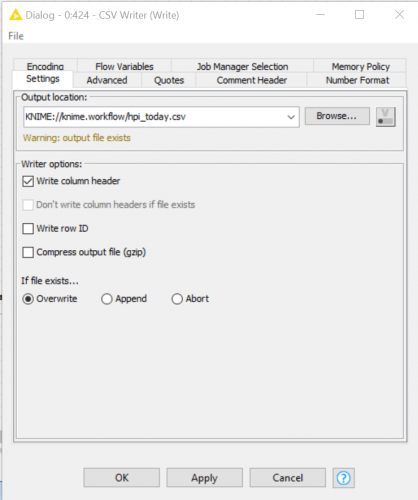
Figure 2
Next, I need to compare the file I just created with the file I created the last time there was a change. I named this file hpi_yesterday.csv. To make this comparison, I joined the files together into a single table using the column appender node (Figure 3).
Figure 3
To compare the data in the virtual table I used the Rule Engine node. Figure 4 shows the example rule I created for my example.
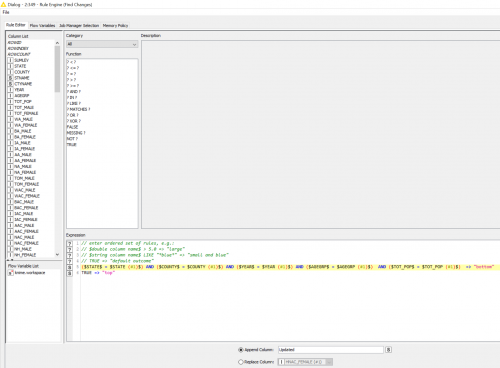
Figure 4
If everything matches, then I set the value to “bottom.” If there is a mismatch, then I use “top.” These are the variables I need to tell the If Switch node to continue processing (“top”) or stop (“bottom”). Before I get there, I group the table based on this new column (Updated) and then sort the value so that “top” will always come first and group by this column so that there is a maximum of two records to check. If I found a change (“top”) then I will continue processing the data, but if all of the records say “bottom” then the process ends.
If you are concerned that this would never work on larger files, I ran this for a 175M file with over 716K records. It took a minute and 45 seconds to retrieve the data and only 30 seconds more to run through the column joiner, compare, sort and group by to get to the if statement. 2 minutes and 15 seconds to ingest two large files, compare the data in these files and decide if it should move forward with the processing feels like a small price to pay for an optimal ETL process.
I hope you consider using this process in the future to optimize your ETL process and only process data that has changed.
