Use Graph Databases for Complex Hierarchies
If you have been paying attention over the past several years, you should have noticed the rise in graph databases. Although we are still in the early adopter’s phase of the Technology Adoption Lifecycle, a few innovative companies are leveraging graph database technology to change how we think about database-driven applications.
For over 40 years, the relational database has been the default concept, even when it should not have been. We have found ways to make relational databases decompose hierarchies with recursive queries and use windowing functions to compare data from the previous or next row. Although these queries can provide one with the correct answer, they are sub-optimal solutions.
Along comes the graph database, and we start to see a more effortless and optimal way to answer these questions. Graph databases were created because of performance and scalability challenges with relational databases.
Let’s take a simple (or not so simple) hierarchy, Elizabeth Taylor’s family tree. I have created a relational data model (Figure 2.) to mimic the data captured and displayed in the graph database (Figure 1.).
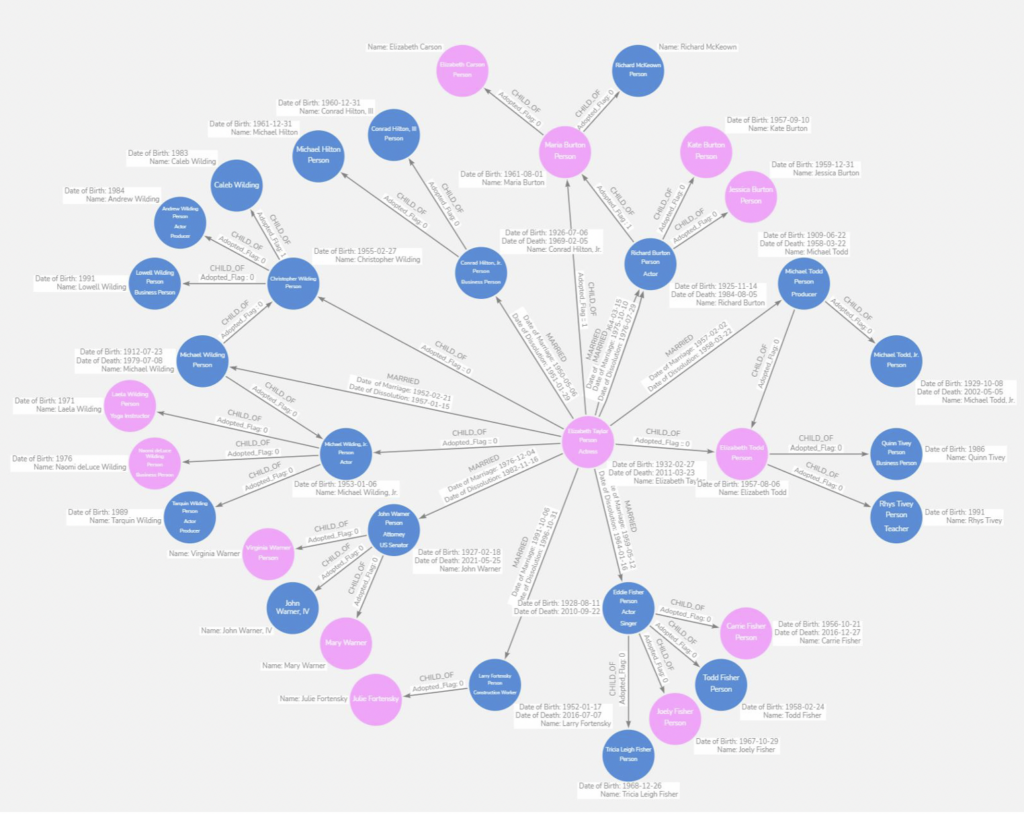
Figure 1 – Elizabeth Taylor’s Family Tree – Graph Database
Not only does the graph model allow us to connect and traverse the relationships between the individuals optimally, but it is also visually pleasing. From this knowledge graph, we can answer many questions using less CPU and memory than the relational database equivalent.
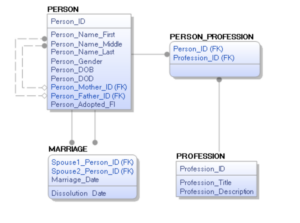 Figure 2 – Relational Family Tree Data Model
Figure 2 – Relational Family Tree Data Model
Now that we have created competing database designs, let’s compare usage and performance by asking questions and reviewing the queries.
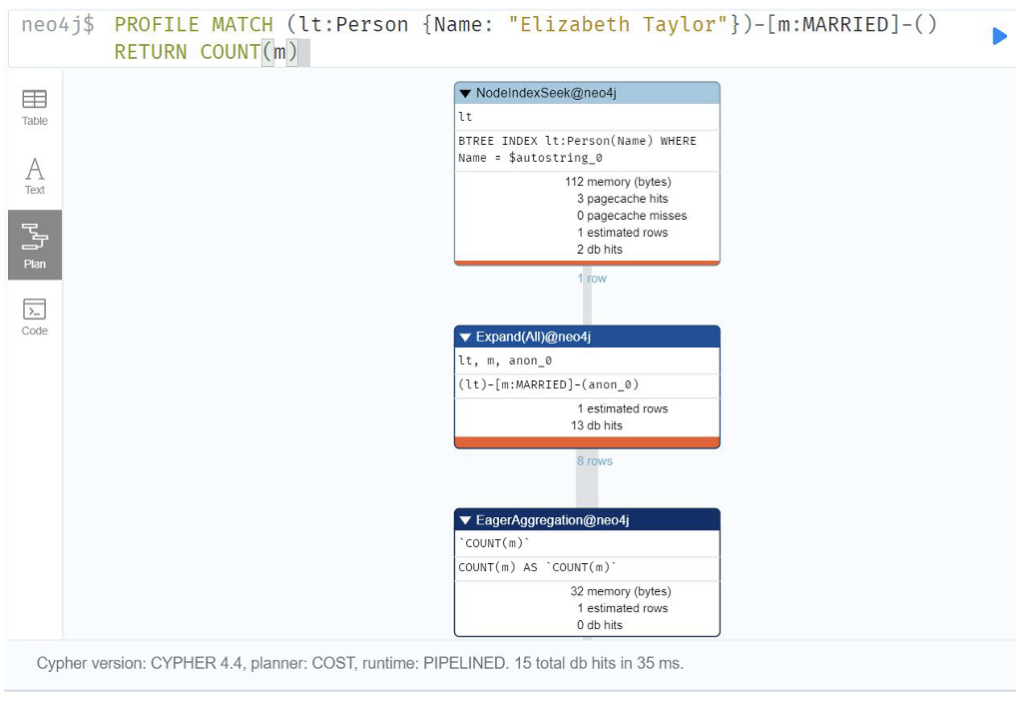
Q1: How many times was Elizabeth Taylor married?
Graph DB:
MATCH (lt:Person {Name: “Elizabeth Taylor”})-[m:MARRIED]-()
RETURN COUNT(m);
Relational DB:
SELECT count(*)
FROM MARRIAGE
WHERE spouse1_person_id in
(SELECT person_id
FROM PERSON WHERE person_name_last = ‘Taylor’
AND person_name_first = ‘Elizabeth’)
OR
spouse2_person_id in
(SELECT person_id
FROM PERSON
WHERE person_name_last = ‘Taylor’
AND person_name_first = ‘Elizabeth’);
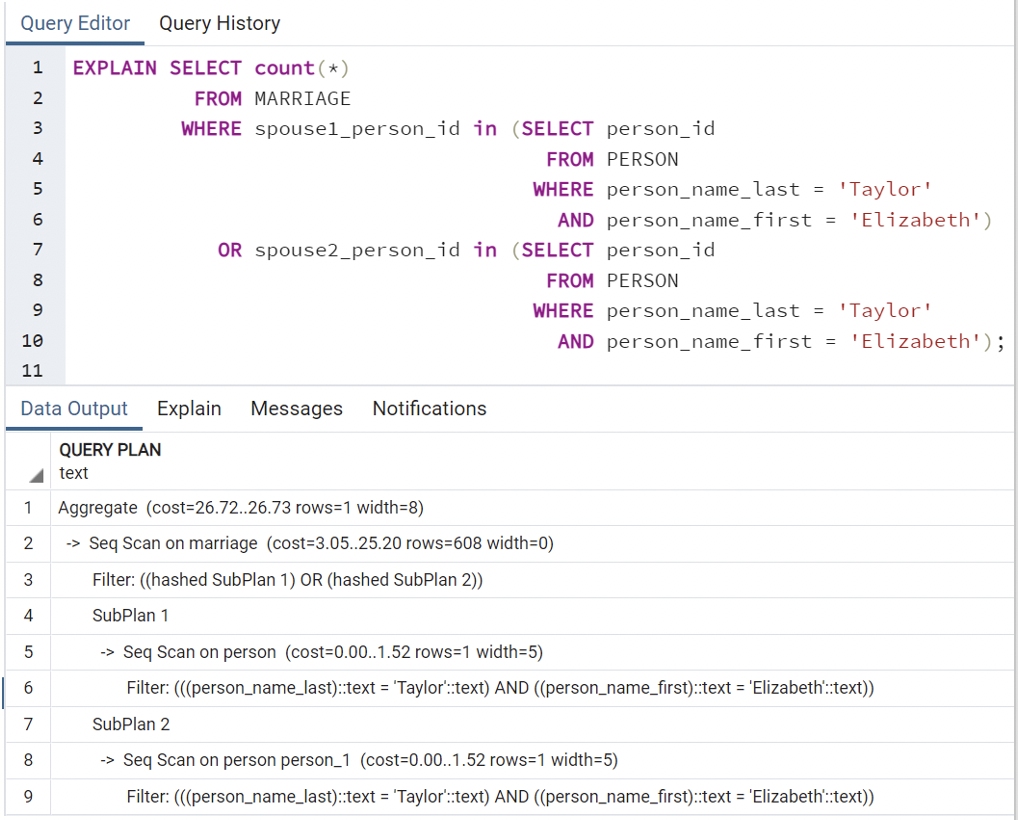
Because of the relational database design and the need for joins between the PERSON and MARRIAGE tables, the graph database will outperform the relational database for these types of queries.
Q2: Were any of Elizabeth Taylor’s children adopted?
Graph DB:
MATCH (lt:Person {Name: “Elizabeth Taylor”})-[c:CHILD_OF {Adopted_Flag: 1}]-(n:Person)
RETURN n
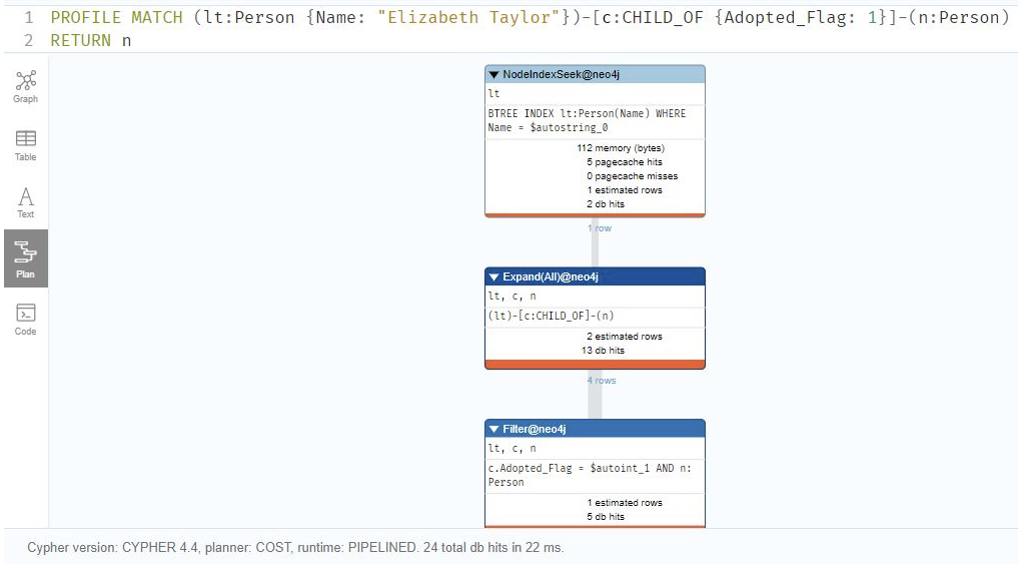
Relational Database
SELECT person_name_first, person_name_last
FROM PERSON
WHERE person_mother_id =
(SELECT person_id
FROM PERSON
WHERE person_name_last = “Taylor”
AND person_name_first = “Elizabeth”)
AND person_adopted_fl = 1;
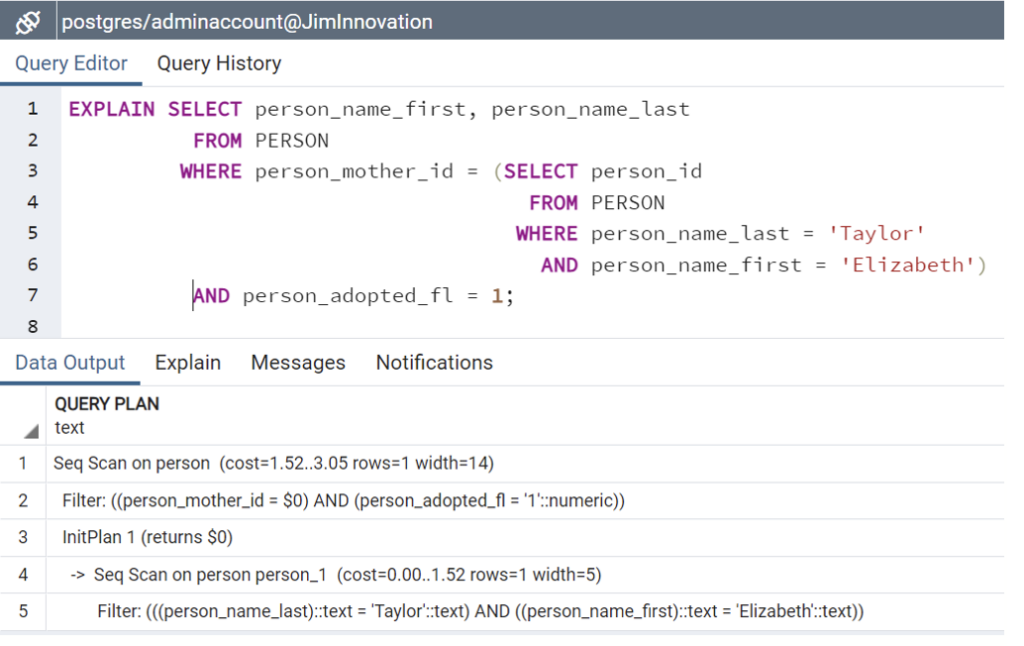
Here is an instance where the relational query is simple, easy to understand, scales well if indexed appropriately, and performs on par with the graph database.
Q3: How many Actors did Elizabeth Taylor marry?
Graph DB:
MATCH (lt:Person {Name: “Elizabeth Taylor”})-[m:MARRIED]-(h:`Actor`)
RETURN COUNT(h)
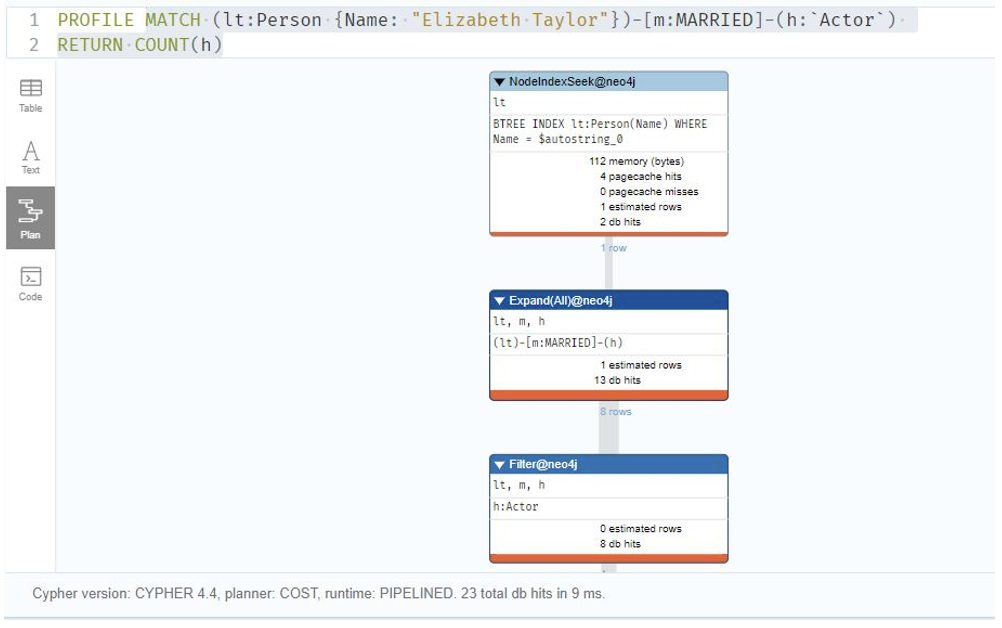
Relational Database:
SELECT count(person_id)
FROM PERSON_PROFESSION PP
JOIN PROFESSION P ON (PP.profession_id = P.profession_id)
WHERE PP.person_id in (
SELECT spouse1_person_id as spouse_id
FROM MARRIAGE
WHERE spouse1_person_id in
(SELECT person_id
FROM PERSON WHERE person_name_last = ‘Taylor’
AND person_name_first = ‘Elizabeth’)
UNION
SELECT spouse2_person_id as spouse_id
FROM MARRIAGE
WHERE spouse2_person_id in
(SELECT person_id
FROM PERSON
WHERE person_name_last = ‘Taylor’
AND person_name_first = ‘Elizabeth’)
)
AND p.profession_title = ‘Actor’;
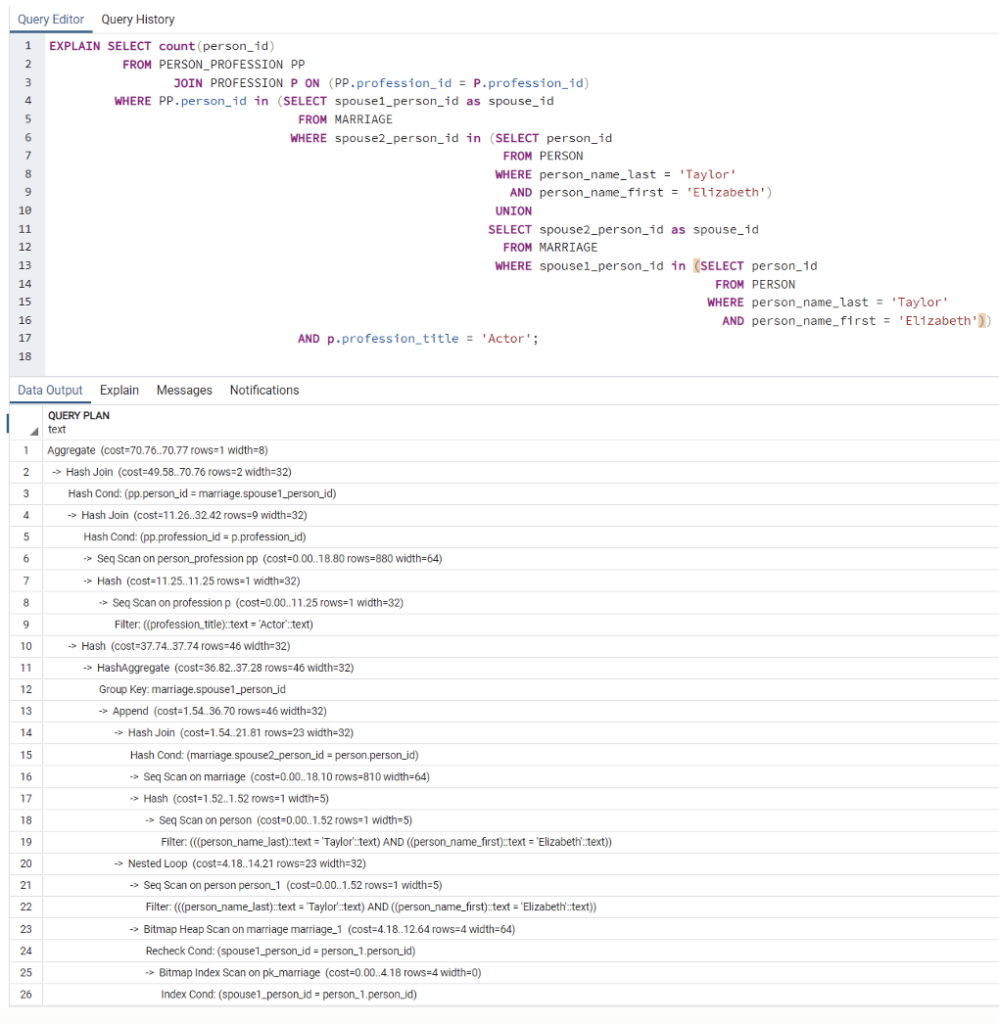
The relational query above is a complex query that doesn’t scale well. It requires more CPU and memory than the graph database to answer the question.
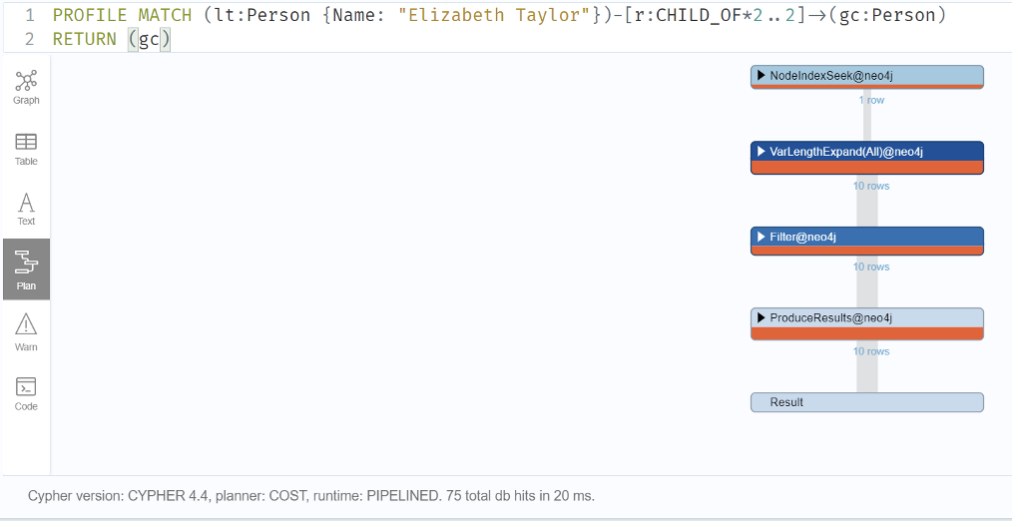
Q3: How many grandchildren did Elizabeth Taylor have?
Graph DB:
MATCH (lt:Person {Name: “Elizabeth Taylor”})-[r:CHILD_OF*2..2]->(gc:Person)
RETURN COUNT (gc)
Relational Database
WITH RECURSIVE grandchildren as (
SELECT person_id
,person_name_first
,person_name_last
,person_mother_id
,person_father_id
,0 AS ancestor_level
FROM person
WHERE person_name_last = ‘Taylor’
AND person_name_first = ‘Elizabeth’
UNION
SELECT p.person_id
,p.person_name_first
,p.person_name_last
,p.person_mother_id
,p.person_father_id
,ancestor_level + 1
FROM person p
JOIN grandchildren gc on p.person_mother_id= gc.person_id or p.person_father_id= gc.person_id
)
SELECT * FROM grandchildren
WHERE ancestor_level = 2;
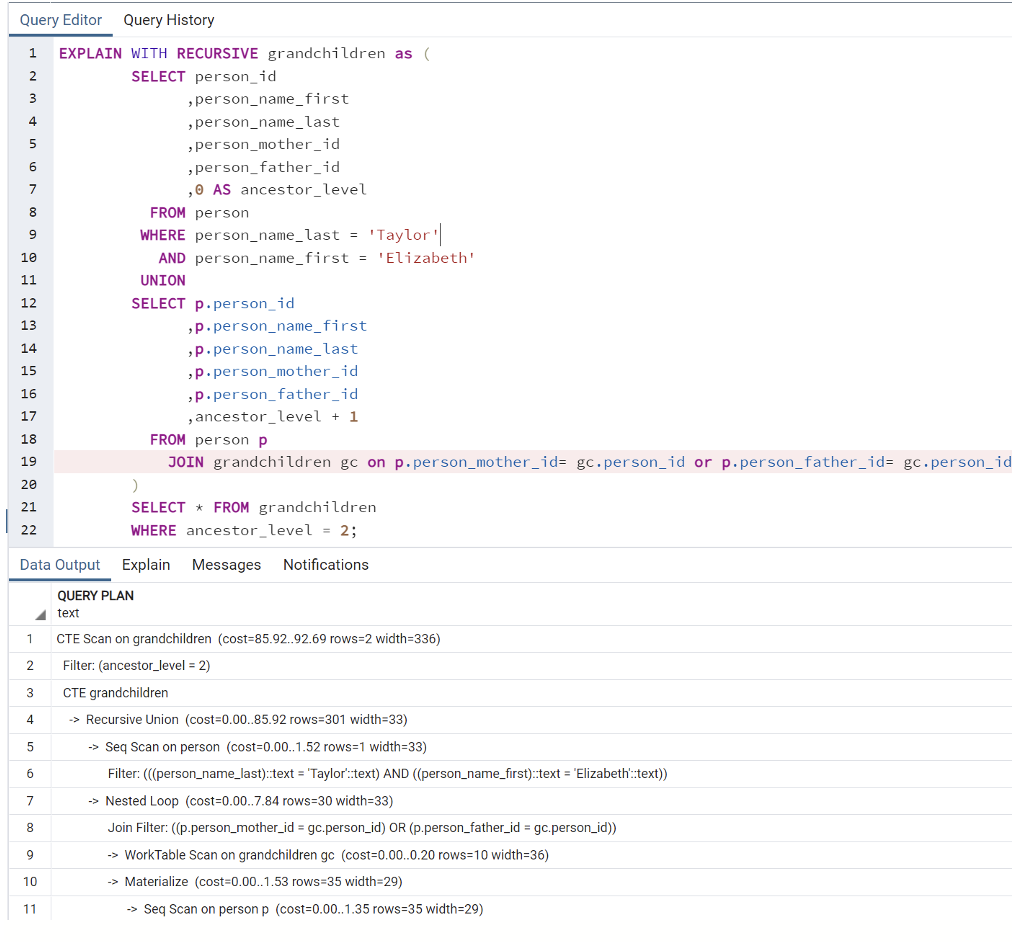
The recursive query above is difficult to write and hard to understand. In addition, this query doesn’t scale well and will require more CPU and memory from the database to answer the same question asked of the graph database. Although relational databases can store and return hierarchical data, they were not designed to do so. Therefore, recursive queries like this should be avoided if possible.
As can be seen from these examples, the graph DB queries are much easier to write and understand and, in general, will scale better than the relational database queries for the example queries above.
The main point I hope you take away from this blog post is to know the application’s requirements and use the correct database or databases as a part of your design. I am not saying that one database is superior to another. They are simply different.
In conclusion, relational and graph databases can harmoniously coexist if designed correctly, providing accuracy, speed, and agility to application developers and users.
About the Author
Jim McHugh is the Vice President of National Intelligence Service – Emerging Markets Portfolio. Jim is responsible for the delivery of Analytics and Data Management to the Intelligence Community.
