Property Graphs: Is it a Node, a Relationship, or a Property?
Introduction
One of the most frequent questions I get asked from new Database Developers and Administrators just beginning to look into Graph Databases is, “How should I model?” They then list some of their strange and specific data needs. They always want a Magic Answer to fix things. Sometimes they have edited ways that a Property Graph Database could accommodate it. Normally, it is very literal as they try to use nodes and arrows to express hierarchies, control, actions, etc.
I’ve found the most helpful direction I can offer these young Graph Database disciples is to reframe their question into, “Is it a Node, a Relationship, or a Property?” This question breaks things down into the smallest units that Property graphs, like Neo4j (which I will be using for all scripts and visualizations in this post), utilize. These data components aren’t as narrowly defined and rigidly utilized as many relational models are, and some of their uses are more abstract. That’s why I focus on Nodes, Relationships, and Properties. Understanding when to use them is vital to anyone creating a new graph database.
Comprehending the Model
If you are new to Neo4j or Property Graphs, I suggest you learn a little more about these components. Neo4j’s Getting Started page has a lot of helpful information. Now let’s dive into a comprehensive side-by-side alignment of these components.
Think about the following scenario. Alice works at Soda Co. Inc. Ltd. at their American River branch. She asks, “Justin, how can we model this?” Let’s see what we can identify as best being a node, what should be a relationship, and what should be a property. Here are three ways to look at it:
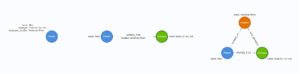
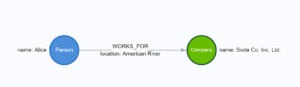
Left: Property-heavy Single Nodes
In the model on the left, all of Alice’s information is listed as properties on a single node. It looks like it handles all our information! We can certainly extend it! There could be Person nodes for Bob and Carol, each with properties for their own employment. This is a very Property-heavy approach.

Some graph newcomers might like this approach, especially if they are attempting to transition over a relational database. Look at the mapping! You could have a very simple relational mapping:
- Everything from the ‘Person’ relational table ends up with a ‘Person’ node in the graph.
- Each column from the ‘Person’ table becomes a property on the ‘Person’ nodes in the graph.
- Each row from the ‘Person’ table gets its own ‘Person’ node in the graph.
You might get to this point and think, “Congratulations! I’ve just converted my relational database into a graph!” While technically that is correct (although a collection of unconnected nodes being called a ‘graph’ is a taxonomic issue), this approach is not taking advantage of how graph databases gain speed over relational databases. Examine how this model gets queried:
- Query for all distinct employers that employ Persons in this graph.
- MATCH (p:Person) RETURN DISTINCT p.employer;
- Query for all employees of Soda Co. Inc. Ltd.
- MATCH (p:Person) WHERE p.employer = ‘Soda Co. Inc. Ltd.’ RETURN p.name;
- Query for all employees who work at the same location as Alice.
- MATCH (p:Person) WHERE p.name = ‘Alice’ MATCH (other:Person) WHERE other.employed_location = p.employed_location RETURN other.name;
How will a Graph Database like Neo4j perform on these queries? Overall, about the same (if not worse) than it would be in a graph database. Neo4j has the fastest access points on labels, then on relationships, and properties (this is an important sentence we’ll repeat later). What does this mean for our queries?
- Query #1 fares well. It is accessing the graph by the Person label, which means it’s going to be accessing the data in question quickly.
- Query #2 is alright, but not great. It’s filtering Person nodes by a property, which might mean it’s a bit slower. We can put an index on that property to help a bit.
- Query #3 is going to suffer since it is doing multiple filters based on a property, and it helps that we’re narrowing that ‘other’ node down to a ‘Person’. As soon as we start trying to compare Person nodes to other types of nodes in our data model (for example, there could be nodes labeled `Office Supplies` or `Delivery Truck` or `Country` that could all want some property to equal Alice’s employed_location), it becomes difficult to build the query and slower and slower to execute it.
This approach is getting good performance for one out of three of our sample queries. You might say, “That’s good, right?” If you’re thinking like this, it’s a very solid mental approach. I’ll tell you the answer to “Should it be a Node, a Relationship, or a Property?” The answer depends on the kinds of queries you want to run against your model. If the only type of information our database is meant to return are queries like #1 (queries that just access nodes via a label and return some properties), this Property-Heavy approach works well. As soon as we need to go beyond that, our query performance suffers. Most databases will likely have to support querying beyond that.
Let’s say it once more, loud and clear, “A good model supports the queries it needs to return in the best performance.”
Center: Relationships and Relationship Properties
Now we will begin examining graph advantages. This graph begins to relate data together with a relationship and adds some definition to that relationship. Notice right away how some of the long property names of the Left approach become a lot more simple and semantically meaningful here in the Center.
The question is, “Is it the best model?” Based on the guidance that the best model is the one that supports our query needs with top performance, let’s look at how we would query our data of interest on this model.
- Query for all distinct employers that employ Persons in this graph.
- MATCH (p:Person) –[:WORKS_FOR]-> (c:Company) RETURN DISTINCT c.name;
- Query for all employees of Soda Co. Inc. Ltd.
- MATCH (c:Company) <–[:WORKS_FOR]- (p:Person) WHERE c.name = ‘Soda Co. Inc. Ltd.’ RETURN p.name;
- Query for all employees who work at the same location as Alice.
- MATCH (p:Person) –[r1:WORKS_FOR]-> (c:Company) WHERE p.name = ‘Alice’ MATCH MATCH (other:Person) –[r2:WORKS_FOR]-> (c:Company) WHERE r1.location = r2.location RETURN other.name;
How is performance looking here?
- Query #1 is still matching on a labeled pattern and getting a single property. It’s probably about as fast as the Left approach.
- Query #2 sees some significant gains, as we’re able to treat each Company as its Node and then access the graph from the point of view of a Company.
- Query #3 still seems to have some issues; a relationship property is not easy to treat as an access point into our graph
Graph databases like Neo4j, excel at relating data together and matching the patterns that exist between them. Now that Company is a node, it’s a much easier access point than when it was a property (always easier to access nodes by labels than properties!).
The takeaway for this section:
When you think of how you will query your data, think of the data elements that drive access into your graph. Nodes, Labels, and Pattern matches are the best way to access a graph. Access to your graph is going to be the driving force for performance and should be the main deciding factor in whether you model data as nodes + labels, as relationships, or as properties.
Right: Single Node Myopia
You likely already know the advantages of the model on the Right, and it’s that Location that suddenly becomes an access point into our graph. We’re going to use this section to talk about how far to take things with node-centricity, but before we do, let’s present that model again and show how to query it.
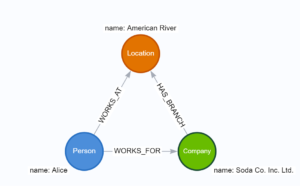
The only query that this impacts is #3, which now looks like:
- MATCH (p:Person) –[:WORKS_AT]-> (loc:Location) <-[:WORKS_AT]- (other:Person) WHERE p.name = ‘Alice’ RETURN other.name;
Look at the performance gain! We now are no longer comparing any properties between separate disjointed nodes/relationships, but we are using a single pattern match to find out everyone who works with Alice. Having Location as an access point into the graph lets us do a lot!
Some readers may think, “Well, why not make everything its own node?” It’s a fair question, but to illustrate its meaning, examine the following thought process:
If companies had four facts about them, there could be a node for the company name, a node for the company logo, a node for the company type, and a node for the company’s founding year. Consider the following models:
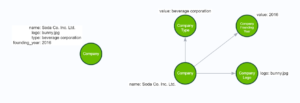
This shows two ways to model Companies; one where the Company is a single node laden with properties, and one where all properties are spread to their nodes. Now that we’ve looked at different ways of modeling, we can analyze these models more critically:
- The Left Person model may seem as limited as the Left Person model was but consider it as part of a larger graph where People are connecting to it. Let’s then take what we learned from the Left Person model and apply it here. If we never have to query our database to filter on or do equals logic between logos, types, or founding years, the Left Company model seems like a perfectly adequate way to model a Company. Some factors, like logo or year, seem very unlikely to be access points for queries, and therefore make good properties.
- The Right Company Model provides access points to company names, types, years, or logos, but that may not be what we want.
- How frequently are we going to be filtering or starting access into a company by its logo? One might imagine that’s not going to be frequent. Maybe we could walk the logo back into a property?
- When looking at nodes for Company type and Founding Year, we may start to imagine how nice it could be to start queries on those. Saying, “Get me all Companies in a specific sector/type,” becomes a lot easier if Company Type is its own node. It is the same for a year, but how often will we need to ask, “Can you get me all companies that were founded in a specific year.” If Company Founding Year is a node, we’ll need to be ready to have one node for every year in our database as well (certainly a size consideration).
- The Left Company model doesn’t allow us to further define logo, type, or founding year. If we need to add more metadata or connections to any of those data elements, treating them as properties is not sufficient.
- One issue with the Right Company model is that if we ever query for company info, we need to write our queries carefully to make sure we don’t miss any information that should go down. Those queries will also be longer as well.
- One advantage of the Right Company model is that it can support multiple logos and company types. The previous model couldn’t handle that without converting those values into Lists, which are among the least-performant kind of graph values to filter on.
These kinds of thoughts begin to reflect an answer to the question: What should be a Property? The best answer I can come up with is: Any data element that isn’t frequently used to access the graph directly, has no internal object complexity/multiplicity, and/or needs to always return with the rest of the data in the node is a good candidate for a Property.
As a side note, if you really enjoyed the idea of separating every fact about a Company into its own node, I recommend you check out the other major type of graph database, the RDF graph model. RDF models attempt to disassemble data facts very much like that Right Company model while still being performant.
Conclusion
This blog looked at the fundamental pieces of a Property Graph database model and the drivers one should consider when employing them in a model. Overall, it demonstrated:
- Nodes and Labels are the best way to access a graph when querying and represent distinct entities.
- Relationships are powerful ways to access different types of nodes at the same time, move through the graph, and filter data. Yet relationship properties can be difficult to utilize for other logic (such as attempting to find equality among different relationships).
- Properties are suited for data that isn’t a point of access directly, can’t be broken down further or duplicated, and/or needs to be considered a component of a Node.
These principles, comprehended over practice and application, help graph modelers understand how to model their data. If you’re just starting to build a graph database, start by listing out as many types of questions you want your database to answer through queries and consider how those queries will be crafted and perform.
Join me on future blog posts where we take the next steps beyond these fundamentals, where we look at Intermediate/Abstract nodes, Multiple-Relationships and Hierarchies, and beyond.
About the Author
Justin Rasband is a Full-Stack Developer at BigBear.ai. He has six years of experience in API development, Javascript/HTML5 coding, and Neo4j data design.

