Structured Query Language Basics
Structured Query Language (SQL) is the standard language used for retrieving and manipulating database information. Today’s blog, I will be focusing on how we can use this language to simply get an organized result set back that answers a specific question. This will be accomplished by using the Select, From, Where, Group By, Having, and Order By clauses
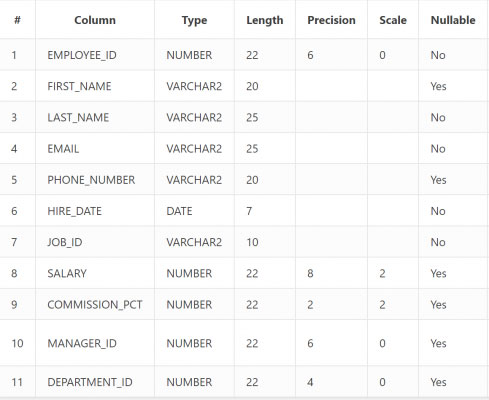
We will be using the EMPLOYEES table in the HR schema from Oracle live as our practice table. You can find the structure of the table in the image below. This can be accessed for free. All you need is an oracle account and login with those credentials. Go to this link (Oracle Live) and select “Start Coding Now”.
SELECT: All SQL statements start with the SELECT. This is how the query knows what information you want to return. The SELECT is where you place the column names, how many columns, column alias, and aggregations you want to see in your result. If you don’t know the structure of the table in advance you can place an asterisk (*) after the SELECT and this will return every column in the table. However the column is named in the table is exactly how it needs to be type in the SELECT statement in order for it to be retrieved. This is before you choose to give it an alias.
FROM: FROM is required in all select statements. This tells the query what table the columns are coming from. If the table you select doesn’t have the specified columns, you will get an error.
Examples:
- Select only email, job_id, and salary
SELECT EMAIL, JOB_ID, SALARY
FROM HR.EMPLOYEES;
- Select every column in the table
SELECT * FROM HR.EMPLOYEES;
- Select FIRST_NAME but give it an alias of F_NAME
SELECT FIRST_NAME as FNAME
FROM HR.EMPLOYEES;
- Notice FIRST_NAME still has the underscore before the alias that is because the query needs to first find the FIRST_NAME column before the query can give it a new name.
WHERE: WHERE comes after the FROM and acts as a filter for the query. You specify what column you want to filter and provide an operator (=,<,>,=>,=<,<>, in, between, like, is null, and, or) and a value that may or may not be in the table. If the value isn’t in the table, the query will succeed but yield no results. For the scope of this blog I will focus on the equal, in, like, and, and or operators.
- Equal (=): Column is an exact match to a value.
SELECT SALARY
FROM EMPLOYEES
WHERE SALARY = 2400;
- IN: This gives the WHERE clause a series of values that may be in the column, and you only want those returned. The values must be placed in parentheses and separated by commas.
SELECT *
FROM HR.EMPLOYEES
WHERE FIRST_NAME in ('TJ','Ki','Guy','Funk');
- Funk is not in the table, but TJ, Ki, and Guy are. They will show in the result
- Strings need to be encased in single quotes and are case sensitive
- Like: IN can use wildcards in the string to allow the user to search a wide variety of results, but unlike IN, LIKE can only have ONE string at a time. There are many wildcards but I will just show you the PERCENT one for today.
- Search for any last names that start with C
SELECT *
FROM HR.EMPLOYEES
WHERE LAST_NAME like 'C%';
- Search for any last names that end in o
SELECT *
FROM HR.EMPLOYEES
WHERE LAST_NAME like '%o';
- Search for any last names that have an i in then.
SELECT *
FROM HR.EMPLOYEES
WHERE LAST_NAME like '%i%';
- AND / OR: The AND and OR operators allow for multiple types of where clauses in a single statement. AND requires that both be true to yield results. OR requires that one be true to yield results. There is no limit to the amount of WHERE clauses you have.
- The result must have a Last name with an i in it and have one of those first names.
SELECT *
FROM HR.EMPLOYEES
WHERE LAST_NAME like '%i%'
AND FIRST_NAME in ('TJ','Ki','Guy','Funk');
The result can have either a salary equal to 24000 or Jobs with names of AD_VP, or FI_MGR.
- If both exists, both will show in the result.
SELECT *
FROM HR.EMPLOYEES
WHERE SALARY = 24000
OR JOB_ID in ('AD_VP','FI_MGR');
GROUP BY: GROUP BY is strictly used when there are aggregations present in the select statement (I.E: SUM, COUNT, MIN, MAX). The purpose of GROUP BY is to take the columns not affected by the aggregate and inform the query that these columns are to be grouped based on their matching result set.
- Count the number of records in a table
SELECT COUNT(*)
FROM HR.EMPLOYEES;
- Because there are no other columns being reference in the select statement a group by is not needed.
- Find the maximum and minimum salaries in the entire table
SELECT MAX(SALARY), MIN(SALARY)
FROM HR.EMPLOYEES;
- Same as above but shows what the minimum and maximum salaries are present in the table.
SELECT MAX(SALARY), MIN(SALARY)
FROM HR.EMPLOYEES
GROUP BY DEPARTMENT_ID;
- And extension of the one before but with a group by column no referenced in the select. This groups by departments and shows multiple records. As opposed to the one before.
- Return the SUM of all salaries in the employee table and grouping them by JOB_ID
SELECT JOB_ID, SUM(SALARY)
FROM HR.EMPLOYEES
GROUP BY JOB_ID;
- The result will have one record for each unique JOB_ID present in the table. Since SALARY is being used with an aggregate, it is not used in the GROUP BY clause.
- I want to know how many people are in each department, and the department’s average salary.
SELECT DEPARTMENT_ID
,COUNT(DEPARTMENT_ID)
,COUNT(EMPLOYEE_ID)
,AVG(SALARY)
FROM HR.EMPLOYEES
GROUP BY DEPARTMENT_ID;
- Notice DEPARTMENT_ID. A column can be both isolated and part of an aggregator. In this case you would still need to place DEPARTMENT_ID in the GORUP BY clause.
HAVING: HAVING is only to be used when a GROUP BY is also used. This acts as a filter for the aggregations. The aggregations used in the HAVING clause don’t need to be in the select statement and the query only returns records that meet the filter.
SELECT JOB_ID, SUM(SALARY)
FROM HR.EMPLOYEES
GROUP BY JOB_ID
HAVING SUM(SALARY) > 10000;
This is an extension of an example in the GROUP BY section. The HAVING clauses makes sure my results only have JOB_ID’s with SALARIES over 10,000 dollars.
ORDER BY: ORDER BY, as the name implies, is a way of ordering the data based on the column you specify. Whether it be descending (abbreviated by desc), ascending (abbreviated by asc), nulls first, nulls last, column position and column name. Ascending is the default and is not necessary for it be in the query, but can be for transparency of the query. The column dictated to the ORDER BY doesn’t have to be in the select statement for it to work, but it does need to exist in the table. The ORDER BY clause is the only place in the select statement that can accept the alias name of a column you put in the SELECT statement. Everywhere else would need the original column name.
SELECT FIRST_NAME, LAST_NAME, EMAIL
FROM HR.EMPLOYEES
ORDER BY LAST_NAME ASC;
Show the result ordered by last_name A to Z
SELECT JOB_ID, SALARY, DEPARTMENT_ID
FROM HR.EMPLOYEES
ORDER BY EMPLOYEE_ID DESC;
Show the result ordered by Employee_ID largest number first.
Notice that Employee_ID is not in the select statement but the order or records would change is removed.
SELECT MANAGER_ID, DEPARTMENT_ID
FROM HR.EMPLOYEES
ORDER BY MANAGER_ID DESC NULLS FIRST;
This result makes sure all records with NULL Manager_ID’s are first, followed by the largest manager_id.
SELECT EMPLOYEE_ID, EMAIL, COMMISSION_PCT
FROM HR.EMPLOYEES
ORDER BY COMMISSION_PCT ASC NULLS LAST;
Have all records with Null Commission_PCT appear last and order it smallest to largest.
SELECT *
FROM HR.EMPLOYEES
ORDER BY 1;
I am selecting every column but ordering it based on the first column in the table. In this case Employee_ID. 2 would’ve been First_Name, 3 Last_Name, and so on.
SELECT *
FROM HR.EMPLOYEES
ORDER BY EMPLOYEE_ID;
Same as the previous example but with the name spelled out.
SELECT EMPLOYEE_ID AS EMP_NUMBER
FROM HR.EMPLOYEES
ORDER BY EMP_NUMBER;
This Order by accepts the alias of the Employee_Id column as EMP_NUMBER
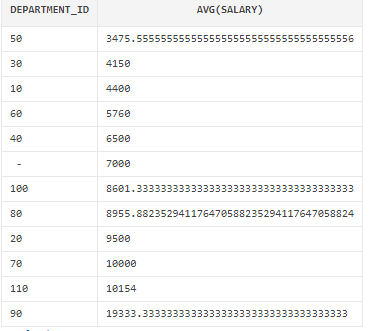
Sample question: What is the average salary between all departments in the employees table? Order by the average salary
SELECT DEPARTMENT_ID, AVG(SALARY)
FROM HR.EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY AVG(SALARY);
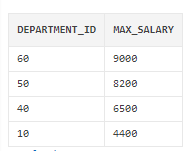
Sample question: Find the max salary in all departments, except for and department id greater than 90, only salaries less than 10,000, order by the salary column descending and rename it as Max_Salary.
SELECT DEPARTMENT_ID ,MAX(SALARY) AS MAX_SALARY FROM HR.EMPLOYEES WHERE DEPARTMENT_ID < 90 GROUP BY DEPARTMENT_ID HAVING MAX(SALARY) < 10000 ORDER BY MAX_SALARY DESC;