The Hidden Cost of Data Virtualization
Define and create a data layer. That was the task my team was handed a few weeks back, with minimal context. The client is a large-scale agency, dispersed both geographically and via network barriers. Applications within this agency run the gamut of legacy, siloed applications owning their on-prem database hardware to cloud-based, database-as-a-service consumers. The main goal for the enterprise is to get away from the “my data” mindset (application-level ownership of data) and decouple data from applications and shift to a more data-centric environment where data is the primary commodity.
Several efforts to accomplish just this had been chartered previously at the agency, most of which identified data virtualization as the solution. More specifically, they proposed standing up infrastructure and creating policy to enable individual applications to expose their data to enterprise users by developing APIs embedded in their existing environment. The main benefits of this, among others, would be the money saved by avoiding rehosting the data, and the incremental, “quick-win” way in which it could be adopted.
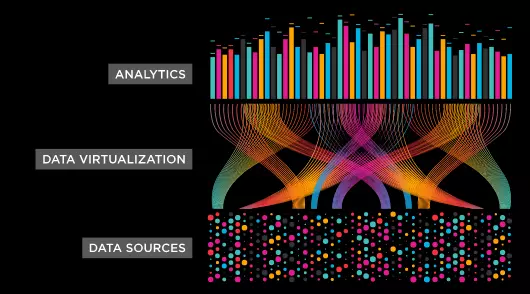
Data virtualization is a great path forward for a lot of organizations to modernize and integrate their data. Many companies provide stellar offerings and several independent technological researchers have deemed data virtualization the best option for creating a more data-centric organization. But this solution does not work in all cases, nor does it address several key challenges caused by implementing data virtualization at the application level. Challenges that very often make data virtualization a suboptimal solution.
First and foremost, while data virtualization does integrate data and make it discoverable, it does not address the decoupling of application and data. The control of the data is still in the hands of application owners, who will continue to control access via the “my data” paradigm. The data has remained in stovepipes and silos, often hidden from potential users who don’t know about the existence of this data. This solution reinforces the idea that the application developers/owners retain control of how their data is accessed by other enterprise users, which is not a goal of this new architecture.
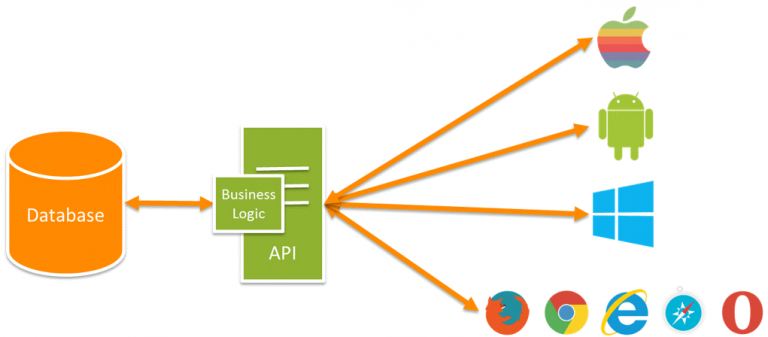
Source: https://snipcart.com/blog/apis-integration-usage-benefits
Furthermore, the development of the APIs to expose the data is the responsibility of the application development team. While this process can be quick (a well-linked and integrated Java web application in the hands of a skilled developer can expose raw data via an API endpoint in a matter of minutes), that is not the case in most instances. Application developers are focused on mission-critical items and need to serve other, more pressing needs than developing APIs. Any new API development has to be racked and stacked against other application feature requirements to find their way into a sprint for creation. After it is deemed worthy of working on, it has to be developed and internally tested, then deployed to a staging environment for testing. Finally, it has to make its way to production. Because of the nature of the strict testing requirements in my industry, this final deployment alone can take weeks. One internal development team estimated a 6-month minimum from feature specification to production functionality.
There are even more downstream effects of the virtualization methodology. Any changes that are made to the API will also need to be routed through this same workflow for the systems needing to use this API. Need a new field? Need another table exposed? Sure, “we’ll try to get to it in the next release.” This reality doesn’t live up to the “quick wins” data virtualization promises to bring to the table.
Additionally, historical data required by business analysts supporting strategical decision-makers and data scientists forecasting numbers may not always be retained in the application. Support for historical data is entirely dependent on the retention policies within the individual applications, which might not be geared towards supporting historical analysis.
There is also the issue of schema changes. What if the application needs to make schema changes due to mission-critical requirements? All downstream consumers of the application’s data – which often not considered for impact analysis – will be affected. These changes can break ETL processes, transformation pipelines, model creation, and dashboards. The data structure changes are often not communicated to the downstream users of the API. These changes are often only discovered when something downstream breaks or someone notices the data has not been updated in several weeks/months. In this same vein, the availability of the data is entirely reliant on the availability of the application. Data is not available should the application need to go off-line for maintenance or experience an unexpected server crash. These issues reinforce an application-centric environment, totally missing the requirement to become a more data-centric organization.
The final challenge when using data virtualization, the issue that is never addressed in any data virtualization whitepapers or research, is performance.
When you call an API to retrieve data, the query runs on the database server, which (in most of the cases in our enterprise) is controlled by and paired with the application. If a data scientist creates a query that is particularly large (i.e., pulling all of an application’s data) it can flood the network with traffic, causing degradation of service across the network. Or when a business analyst creates a particularly complex query that joins several different data tables together, the query may be computationally expensive. Because the data is being accessed via an API, running on the application’s hardware, that computational cost (CPU and memory) is extracted from the application’s resources. This CPU and memory that would otherwise be serving the mission-critical customers is now serving a “third-party” analytical query. This outside consumption of application resources can cause lag times and can even cause applications to crash.
I have seen this happen to two highly mission-critical applications in the recent past. To avoid the system from crashing, one refuses to expose APIs, preventing unknown users from “mucking around in their database.” Another system replicates their entire database multiple times in order to support the API calls they receive. The efficiency that data virtualization promises is effectively compromised in this manner.
Not only does the application’s performance suffer, but those relying on their queries to return data suffer as well. Because the application server hosting the data is not optimized for bulk pulls or analytical queries, data access is a bottleneck limited by the database’s compute power and the network needed to transfer the large volumes of data. Some queries may never return! All it takes is one cartesian join and boom, mass chaos.
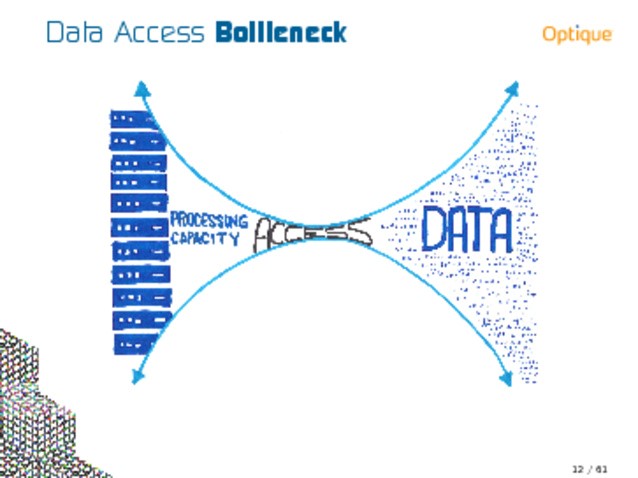
Source: https://www.slideshare.net/MartnRezk/slides-swat4-ls
The promise of data virtualization at an application level is often overvalued. There are too many situations where data virtualization negatively impacts the enterprise-wide data consumption. Data virtualization is a viable solution that will work for some organizations. However, for large enterprises, we need something more flexible, scalable, and easier to implement. And we need a solution that has minimal (if any) impact on the underlying, mission-critical transactional applications that host the data. While getting data into the hands of business intelligence analysts and data scientists is essential, it should not interfere with everyday transactional systems and tactical decision making.
My team is still in the process of determining the right solution to our problem. Nevertheless, we understand that for the reasons stated above, data virtualization would be a sub-optimal solution given our requirements. Perhaps an enterprise data hub that leverages an operational data store would be a more optimal solution.

