Leveraging Athena with KNIME in a Robust Manner, Part 1
Recently, we began experiencing seemingly random intermittent failures in one of our modeling workflows used in VANE, an advanced predictive analytics project we are building for the US Army. These failures were occurring with varying frequency inside of any one of several Database SQL Executor nodes. These nodes were performing a large number of SQL queries against Amazon Web Services’ Athena backed by a large number of data files in S3. The workflow was randomly failing in any of these nodes with a HIVE SPLIT error due to a missing partition file in S3.
When we investigated the failure, we would invariable find the supposedly missing partition file and restarting the workflow from the failed step would succeed. With a little bit of research, we learned that this is a known problem with Athena and S3 storage due to the nature of S3 being “eventually consistent”. Simply put, some of the Athena queries were being executed before their required data files were fully materialized in S3.
With this newfound knowledge, we began to consider ways to make our workflow more robust and able to recover from these transient failures. If our Athena usage was small, we could have simply broken each statement into its own SQL executor node and included delays or retry loops for each node. However, in our very complex modeling we had multiple SQL executor nodes and each one had anywhere from a handful to several dozen queries that they were executing. Breaking all of these queries into a query per node was not a viable solution, particularly when each node would need its own surrounding retry logic for any intermittent failures.
To address this complexity, we decided to extract all of the Athena queries into external files and create a meta-node that could accept a table of queries and execute them sequentially with the ability to retry any individual queries that fail up to an arbitrary number of times before aborting the workflow. We quickly set up a workflow using looping node to loop over all of the SQL statements and set a flow variable named query to each one in turn. The Database SQL Executor node was then configured to use this flow variable as the statement to execute.
And then we hit a big snag in this plan. Many of our queries leveraged the Database SQL Executor node’s ability to insert flow variables dynamically using the $${var name} syntax in its statement source. This meant that many of our statements looked like the following:
drop table if exists ${SathenaTempDB}$.temp_dedup1;
create table ${SathenaTempDB}$.temp_dedup1
WITH (
format = '${Stemp_file_format}$',
external_location = 's3:/${Stemp_table_scenario_dir}$/dedup1/'
)
as
select source_name,measure,country_trigraph, source_date,provenance
from ${SathenaTempDB}$.temp_gf_output t
group by source_name,measure,country_trigraph, source_date,provenance
having count(*) > 1;
The issue we encountered is that the Database SQL Executor node does not do this variable substitution if its statement to execute is bound to a flow variable; it just uses the value of the variable directly with no flow variable reference resolution. This is arguably a design flaw in the node itself, but we did not have the time to develop our own fix to the node and submit it to KNIME. We were left in the situation of having to implement our own arbitrary flow variable substitution so that we could pre-process each SQL statement before it was executed.
Fortunately, KNIMEhas a very nice little feature that lets you dynamically reference flow variables from code in the Java Snippet node. This is done via the getFlowVariable(name, type) method in the code. Using this method, we are able retrieve the value of any flow variable referenced inside a SQL statement without having to directly configure it in the Java Snippet node.
All that was left was a little bit of regular expression magic to come up with the following pattern that leverages capture groups to allow us to dissect an embedded flow variable reference from the SQL statement:
Pattern EMBEDDED_PATTERN = Pattern.compile("(.*?)\$\$\{(.)([^\}\s]+)\}\$\$(.*)",Pattern.DOTALL);
It is important to note the use of the DOTALL pattern option here; this option enabled the expression to match across multiline statements. Furthermore, this pattern is designed to capture the first embedded flow variable reference and treat any additional references as just part of the remaining string. This was done so that the expression can be used to loop over a single source statement and resolve the embedded flow variable references one at a time.
When there is a match, the pattern matcher will return up to four capture groups that contain any statement preceding the match, the referenced flow variable (and its type), and any statement after the flow variable reference (possibly including other flow variable references:
String begin = matcher.group(1); String type = matcher.group(2); String variable = matcher.group(3); String end = matcher.group(4);
For example, for the statement:
drop table if exists ${SathenaTempDB}$.temp_dedup1;
The above group variables would be set as follows:
begin = “drop table if exists” type = “S” variable = “athenaTempDB” end = “.temp_dedup1;”
The processing for each match is simply rebuilding the source statement but inserting the referenced flow variable’s value between the beginning and ending sections of the statement. Because flow variables have a type and the getFlowVariable method requires this type to be specified, we have to to retrieve their value based on the type designator that the KNIME Database SQL Executor Node inserts in front of the variable. This type is extracted into its own capture group, so we just use it as follows:
String value;
switch(type) {
case "S" :
value = String.valueOf(getFlowVariable(variable, tString));
break;
case "D" :
value = String.valueOf(getFlowVariable(variable, tDouble));
break;
case "I" :
value = String.valueOf(getFlowVariable(variable, tInt)); break;
default :
value = "UNKNOWN";
}
This technique could also be extended to support other types of embedded references. For example, we could arbitrarily define the type of “E” to reference an environment variable as follows:
case "E" : value = System.getProperty(variable); break;
By extending the regular expression and including another capture group we could also allow for the optional declaration of a default value to be used if a flow variable does not exist. For example, we could use the pipe separator to declare that everything after the flow variable name is the default value for the variable (e.g. DefaultDB in the following example):
drop table if exists ${SathenaTempDB|DefaultDB}$.temp_dedup1;
While I will not dive into the actual regular expression for defining default values in this blog post, this is a very power technique that I frequently leverage in my Java code and I am working on a more detailed future blog posting that will cover a more general embedded expression resolver that is leveraged frequently in much of our backend and middleware services.
Getting back to the problem at hand, we can put all of the pieces together with just a little more code to reassemble all the extracted groups back into a query statement. This gives us the following complete Java Code Snippet code block:
Pattern EMBEDDED_PATTERN = Pattern.compile("(.*?)\$\$\{(.)([^\}\s]+)\}\$\$(.*)",Pattern.DOTALL);
String sourceString = c_query;
Matcher matcher = EMBEDDED_PATTERN.matcher(sourceString);
while (matcher.matches()) {
// We have an embedded reference so resolve it and rebuild the string.
String begin = matcher.group(1);
String type = matcher.group(2);
String variable = matcher.group(3);
String end = matcher.group(4);
StringBuilder builder = new StringBuilder();
if (begin != null) {
builder.append(begin);
}
String value;
switch(type) {
case "S" :
value = String.valueOf(getFlowVariable(variable, tString));
break;
case "D" :
value = String.valueOf(getFlowVariable(variable, tDouble));
break;
case "I" :
value = String.valueOf(getFlowVariable(variable, tInt));
break;
default :
value = "UNKNOWN";
}
builder.append(value);
if (end != null) {
builder.append(end);
}
sourceString = builder.toString();
// Now reset the matcher to see if there are any more embedded references.
matcher = EMBEDDED_PATTERN.matcher(sourceString);
}
As an aside, one interesting side effect of using a loop like this to reprocess a statement repeatedly until all flow variables are resolved is that nested references are also supported. That is, if a flow variable’s value also contained a reference to another flow variable, it would be resolved in a subsequent pass through the loop.
This code requires only one input and output variable to be configured in the Java Snippet Node: the query column that is being processed to be executed by the Database SQL Executor node. This is done as follows:
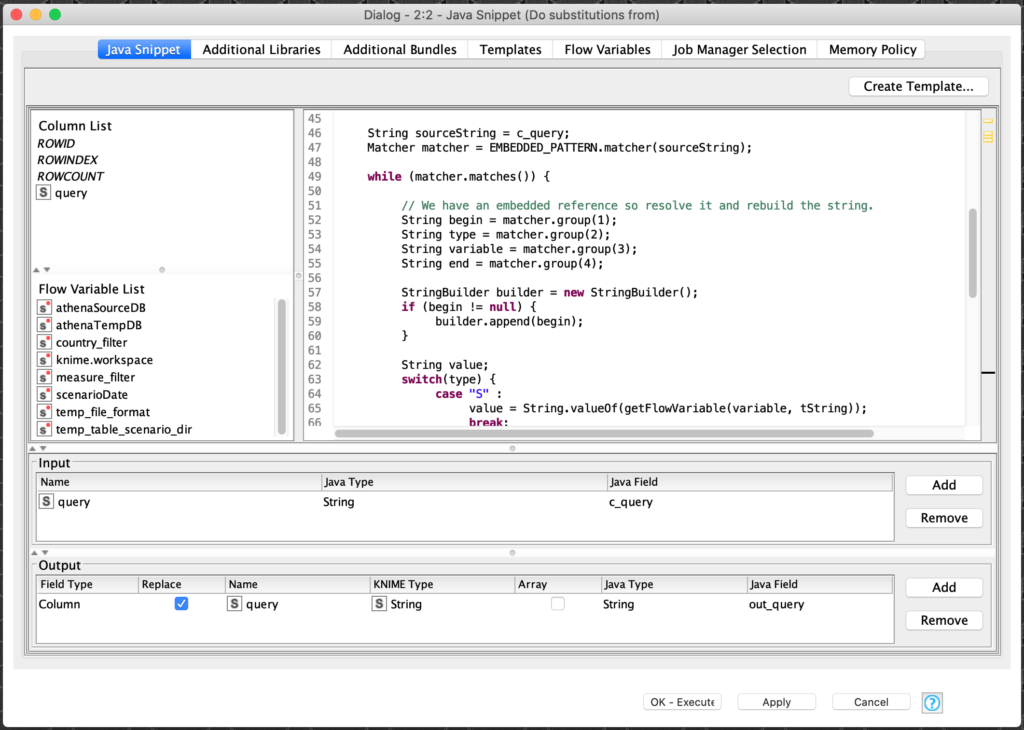
With that, we can now preprocess a loaded table of Athena query statements to resolve any embedded flow variable references and then execute them one at a time via a Database SQL Executor node with the appropriate error detection and retry logic. The workflow to implement this will be covered in part 2 of this article which can be read here.
