What the Farkle? Recursion, Modeling, and Genetic Algorithms with KNIME, Part 1
My wife and I love to Farkle and it drives our kids crazy. Don’t be offended; Farkle is a dice game played with six dice for two or more players. My wife has a PhD in Global Public Health and has often taught epidemiology to master’s level students which means she has a great appreciation for statistics and data science too. She and I love this game because even though the odds are governed by the basic combinatorics of six-sided dice, the player can make many choices which affect the odds throughout their turn. We’ve had many a spirited debate as to what the best choice is in many of those situations. And even though we both consider ourselves scientists, we often find ourselves joking about runs of bad luck and hot streaks. Our frequent strategy debates led me to start thinking about how I would model the game to see if I could come up with the optimal behavior for each situation in the game. In short, could I build the optimal Farkle player algorithm?
The open source KNIME data science platform was the ideal tool for tackling this problem. It let me quickly and interactively explore the combinatorics of the game and try out approaches for testing various methods for modeling play behavior. In this series of blog postings, I’m going to guide you through my explorations of the game which led me to come up with a way to use genetic algorithms to evolve the best Farkle player algorithm I could. Along the way, I will present some interesting modelling techniques. I will also show how to use the KNIME recursive loop nodes to perform open ended processing where the end state cannot be predetermined. Today, in part one, I’m going cover the basics of the game, some of the basic roll statistics, and how I modeled player behavior so that it could be optimized using a genetic algorithm.
Farkle is played in turns with each player taking their turn before passing the dice on to the next player. On a player’s turn, they start by rolling all six dice and selecting which ones to score and which ones to reroll (if any). The scored dice are set aside, and the player then rerolls the remaining dice if they would like to. If no dice score points, the player has “farkled” and they forfeit their score for that turn. The player may continue to keep rolling as long as they do not farkle and elect not to stop. If the player is lucky enough to score all six dice, they may continue rerolling with all six of the dice. If the player stops rolling before they farkle, they add their turn’s score to their total score and play continues to the next player. This is repeated until the first player reaches 10,000 points. At that point, all remaining players have one final to turn to see if they can beat the first player’s score. Those players keep rolling until they either beat that score or they farkle. This is the basic game; for more details, you can read about the game here.
There are many variations to the scoring rules for Farkle. Over the years, we have refined our variation to the following scoring table:
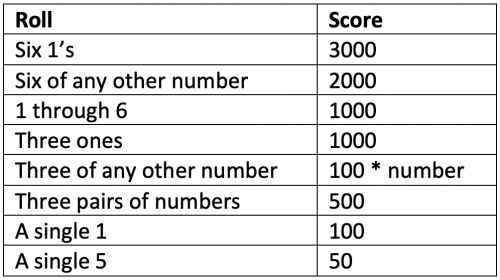
With scoring, the important thing to understand is that it is the player’s decision what dice to score and what dice to re-roll if they want to continue rolling on that turn. For example, say I were to roll a 1, 1, 2, 4, 5, and 6 on my initial roll. I could score this roll in any one of four ways:
- Score both single 1’s for 200 points and the single 5 for 50 points which is a total of 250 points, and I can choose to reroll the remaining three dice.
- Score one of the single 1’s for 100 points and the single 5 for 50 which is a total of 150 points, and I can choose to reroll the remaining four dice.
- Score just one of the single 1’s for 100 points and reroll the remaining 5 dice.
- Score just the single 5 for 50 points and reroll the remaining 5 dice.
And this is where the player’s choice affects their likelihood of scoring lots of points. We have four choices for the roll above: should you aggressively score all the dice you can and reroll the fewest, or even just stop rolling and keep your turn’s score? Do you only score the fewest dice you can so that you can reroll more dice and have a chance at getting a bigger score on that next roll? Or do something in between like score the higher scoring dice like the 1’s but not score the 5 so it can be rerolled? In essence, what is the choice that optimizes the risk versus reward?
My initial analysis was just to look at the basic dice combinatorics. Mathematically, you can calculate the total number of possible rolls of n six-sided dice as 6^n. But just knowing the total number of rolls won’t help me when it comes to the game itself; I need to know the actual rolls themselves and which ones actually score versus which one are “farkles” (no scoring dice). KNIME is great for this so I wrote a KNIME workflow to generate all possible dice combinations and analyze them. You may find the workflow on the KNIME hub.
From a data generation standpoint, there are two loops required to generate all possible dice rolls in Farkle. The first loop is for the number of dice being rolled (one to six). The second loop is for all possible rolls for that current number of dice. But there is an interesting optimization hidden here: when you have 6^n possible combinations for n dice, you can enumerate them numerically if you can come up with a function to map the any given number in the domain to the set of dice it represents. In this case, that function just requires basic modular arithmetic.
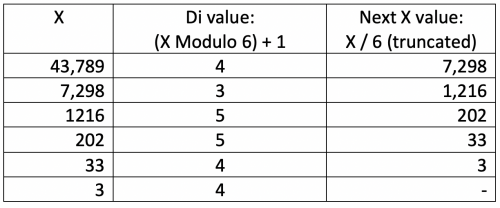
Starting with the current number, the value of the number modulo 6 gives you the value of a single di when you add 1 to it. You then divide the number by 6 and drop any decimal portion to get a new starting number. If you do this n times for the number of dice, you’ll have the set of dice that the starting number represents. For example, with 6 dice, the total number of combinations is 46,656 so we will arbitrary pick roll number 43,789 to apply the process above to with the following results (X is the starting number):
With our function in hand to map from our index number to set of dice, the first inclination in Knime would be build two loops with a dice index loop nested inside a dice count loop. While this would work, there is a very clever optimization you can do here to eliminate the inner loop and make this section of the workflow run faster. Since I know the total number of dice rolls for any given number of dice, I can simply create an empty table with that many rows at the start of the dice count loop and then generate the dice set for each empty row in the table:
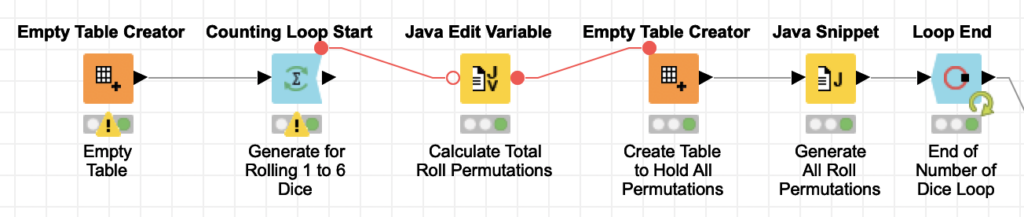
Inside the outer dice count loop, we are using the current iteration flow variable to calculate the total number of permutations for that number of dice in a flow variable as follows:
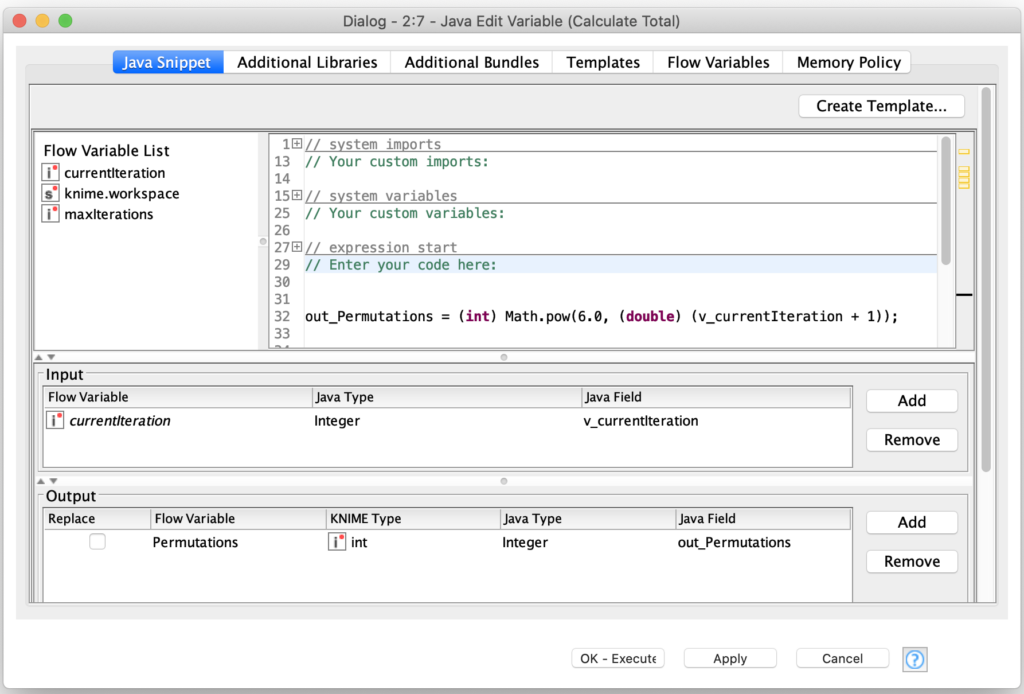
I then use the Permutations flow variable inside the Empty Table Creator node to create a table with that number of empty rows. The trick here is that even though the following Java Snippet node is just processing empty rows, it has access to a row number flow variable which it can apply the dice mapping function to. That function’s result is then combined with a little more code to turn the set of dice values into a single string value:
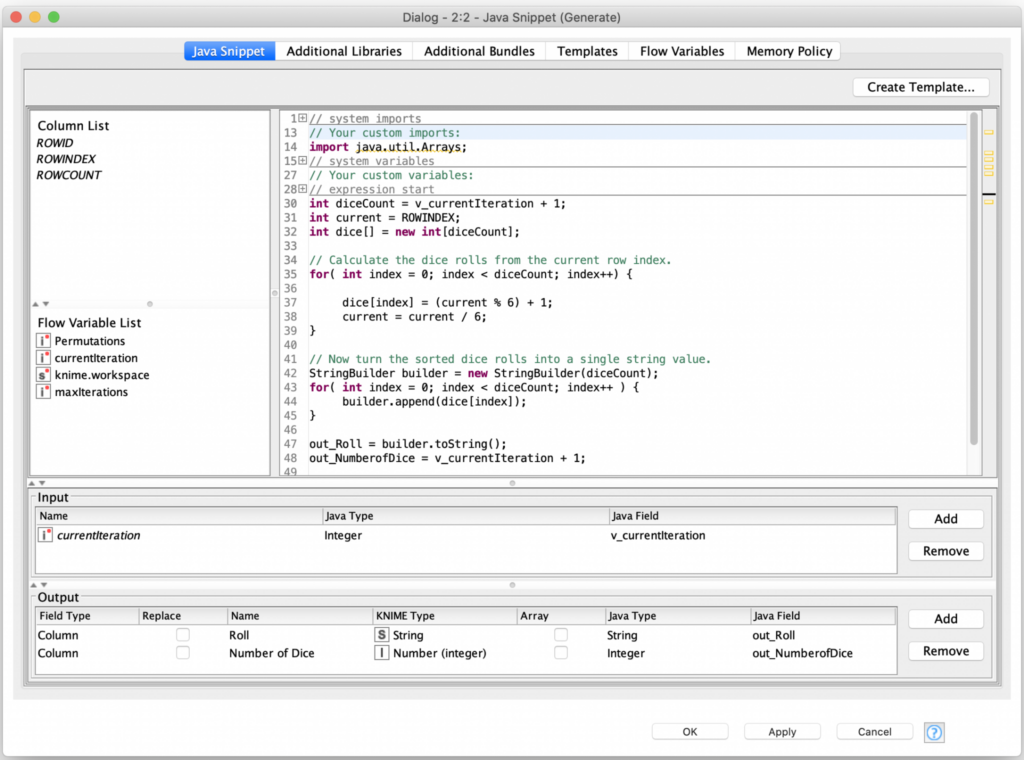
The output from this node give you the dice roll, and the number of dice that were rolled:
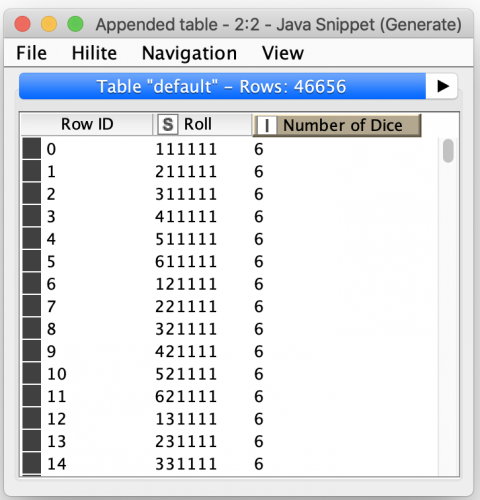
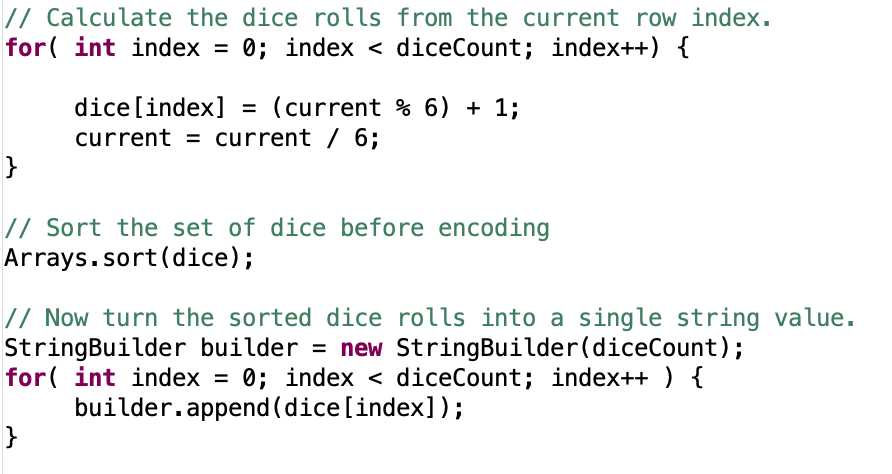
While this is the comprehensive list of dice rolls, there was a gotcha lurking in it with the way I modeled the roll output. I’ve been referring to the set of dice for a given roll number but then encoding it as a string. By doing so I had imposed an arbitrary ordering on the way the roll was encoded and made it very difficult to identify equivalent rolls since it is often possible to roll the same combination of dice in many different ways. For example, when rolling two dice, you can roll a 1 and 5 or also roll a 5 and 1. To accommodate this, I just needed a simple optimization in my Java snippet: I can sort the set of dice by value before I encode it into a string:
With the revised output, I was able to confirm that the total number of possible rolls was 55,986 which matched my math calculations. By grouping on the roll string, I was then also able to count the actual unique roll combinations which surprised me by being only 923 total unique combinations when rolling anywhere from 1 to 6 dice, broken down as follows:
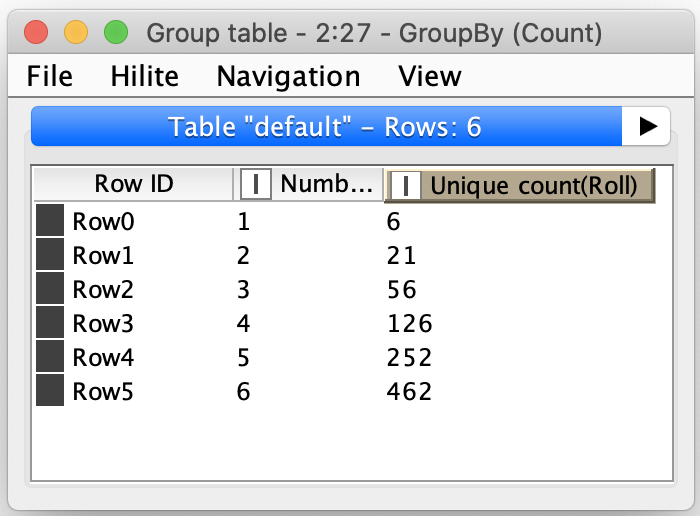
This information is not particularly useful since it gives me no way of determining which rolls would score points and which rows were non-scoring farkles; I needed a way to score the rolls. Fortunately, I had already written a Java Farkle scorer for some past experiments that I did a while ago when my wife and initially became obsessed with the game. I ran my scorer against the workflow’s output of all possible Farkle rolls and saved all possible scoring combinations for each roll. Along with the score, I also saved the number of dice that could be rerolled based on which dice were selected to be scored (a count of zero represented that all dice should be rerolled.)
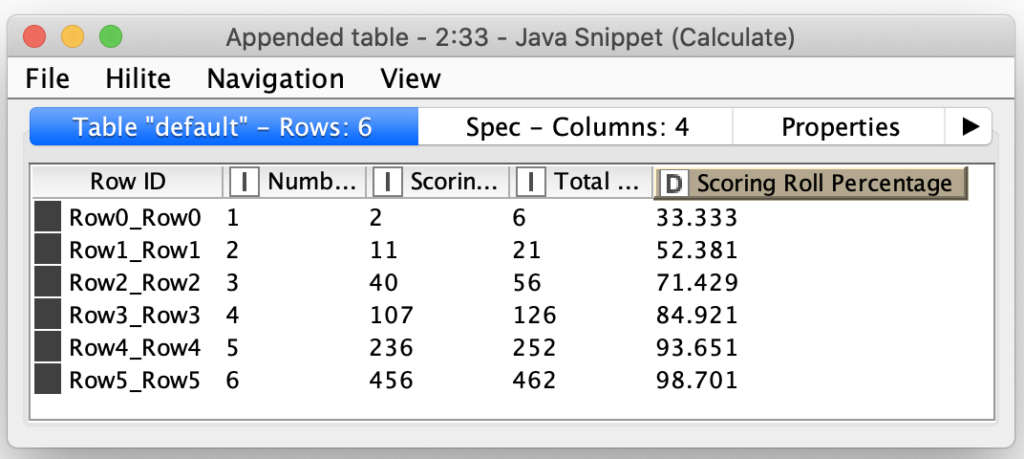
From this output I learned that there were 3150 ways to score the 923 unique roll combinations. By counting the unique rolls that score, we can combine this with the total roll counts and calculate the percentage of rolls that score for each number of dice that can be rolled in a game:
This analysis also shows me that of the 923 roll combinations, there are 852 unique dice combinations that score points which means that there are 71 dice combinations that are considered farkles.
Given all this information, it seems like the basic strategy should be to score whatever combination of dice results in you rerolling three or more dice since that always gives you greater than a 71% change of scoring more points on the reroll. If you can only reroll two dice after scoring your dice, you should stop rolling. But we do not know if this behavior will maximize your points in all situations. For example, if you have three 1’s in your initial roll of six dice, does it make more sense to score the 1000 points and only reroll three dice? Or should you only score a single 1 for 100 points and reroll the remaining five dice since that greatly improves your odds of not getting a farkle (as well as giving you a better chance at scoring higher points on the reroll?)
When presented with a problem that involves lots of independent odds calculations and possible branches of behavior that makes it impossible to systematically explore every possible game permutation, my thoughts turn towards implementing a Monte Carlo simulation so that I can play a large number of games evaluating different sets of choices and empirically determine which set of choices results in better overall game outcomes.
In order to take that approach, I needed a way to model the possible choices in the game. Fortunately, my initial explorations of the various roll statistics have hinted at a very clean way to model player behavior. Since I discovered that there are only 852 possible scoring rolls, any player’s decision state can be modeled by storing their choice of what they would do for each of those rolls. And that decision would look like a combination of the factors of which dice they would score, and how many dice they would reroll (including the choice of not rerolling any more dice.)
In addition, we also have the score data which contains all 3,150 possible scores. And this data represents every possible choice a player can make for all possible score rolls. Combined with the binary decision of whether or not to continue with rerolling their remaining dice, this gives us a total of 7,300 possible player choices in a game.
Putting this together, a player’s behavior is a map of all scoring dice rolls to a pair of choices. The first value represents the selected scoring choice out of the available choices for that roll. The second choice is a binary value that indicates whether or not the player will choose to continue rolling or stop with their current turn score.
With this we have a way to model player behavior, but it is important to realize that it is simplistic. Most importantly, there is no consideration of the total score a player has accumulated in a turn already and how that might affect their perception of risk versus reward for continued rolling. For example, if a player has managed to accumulate 1,500 points in the current roll, they may be less likely to continue rolling three dice (and risk losing those points) than if they have only accumulated 200 points so far. For my initial explorations of optimal Farkle behavior, I decided to accept this limitation of my model. If I can find success with the simpler model, I can then revisit the model and see if I can introduce a means for capturing accumulated point balance in a more sophisticated model.
Now that I have a way to model a player’s decisions and have picked a Monte Carlo simulation approach to score the results of any given player, the final piece of the puzzle is how to come up with players to evaluate. Given that each player’s decision map is 852 elements with a large number of choice pair combinations to map to, it is not practical to programmatically generate the set of players that represent the entire domain of possible player behaviors.
It is this reality that brought me to considering a genetic algorithm approach for refining player behaviors. If I can generate an initial set of players and score them against each other, I can then select the fittest players and “breed” them to produce a new generation of players to test. Repeating this process over many generations could potentially lead me to evolve better and better Farkle players. This is what I will cover in my next blog posting; I will dive into how I used KNIME to implement a genetic algorithm for evolving the optimal simplistic Farkle player.
The process of data science is an open-ended journey where initial explorations often shape the modeling of future steps. As I’ve shown in this article, care must be taken to always consider the implications of how you represent data (i.e. the dice roll string) and how you model the problem (i.e. the player choice table). By diving into this exploration with a powerful tool like KNIME, I was able to quickly understand the characteristics of the problem I laid out for myself and find a way forward to model it for future exploration and refinement.
I will be back in two weeks with the second part of this post and in the meantime, I encourage you to go Farkle yourself. You might just find yourself as obsessed with game as my wife and I are.
