What the Farkle? Recursion, Modeling, and Genetic Algorithms with KNIME, Part 2
In the first part of this blog series, I introduced the dice game called Farkle and explored some of its basic statistics related to the combinatorics of rolling 6 dices and choosing how to score them in the optimal manner. From this initial analysis, I discovered that there are only 852 unique dice combinations that score points. Furthermore, there are only 3,150 possible moves for this set of combinations and after each move there is a Yes or No choice to continue rolling.
The combination of these discoveries led me to the realization that a Farkle player’s behavior can be simplistically modeled as a mapping from each of these possible dice combinations to one of the valid moves for that combination and the continue rolling choice. In KNIME, we can represent this mapping as a set of rows with just a few columns: the dice roll, the points scored, the number of dice to re-roll, and whether or not to just take the score or continue to roll.
Ideally, we could try every combination of these choices to determine which one results in the best overall win rate. But if we consider that each unique scoring dice roll has on average 3.68 possible choices for how to proceed and an associated Yes/No choice for if the player continues rolling, the total number of players required is in the order of 2 x 3.68^852 or approximately 2.53 × 1022. With 853 separate parameters to tune, the parameter optimization loop approach I covered in my Making the Pass blog series won’t work – it is simply impossible without near infinite compute resources.
But maybe we can take a similar approach as the parameter tuning nodes where we start with a series of random players and score each of their performances? Then we could pick the best scoring players and attempt to extract the best aspects from them for a new set of players to test. This is a genetic algorithm: a programmatic approach to trying to replicate the effects of evolution and natural selection to optimize for a behavior we are seeking.
In our case, the behavior we are trying to optimize for is an effective Farkle strategy and the “genetic code” of a player is their table of move choices. To further extend the genetic metaphor, we can then “breed” a new generation of Farkle players by mixing the genetic code of the best players of the current generation. In other words, maybe we can make the next generation of players by randomly combining the move tables of the top players from the previous generation.
So now I have a way to model player behavior and a way to evolve it, but how do I find the top players? You may recall from the first blog that I noted that the player move table is simplistic; it does not allow for the consideration of changing player strategy depending on where they are in the game and how many points they’ve already scored in their turn. It is essentially table for mapping the optimal choice for a given dice roll. Given that I’ve already made this assumption, I also use it to come up with a simpler scoring metric. Since there is no overall game state consideration in the roll table, I can score a player by using their move table to play a large number of independent turns and calculate their average roll score.
For my initial exploration into genetic algorithms, this will suffice. In the future I can definitely enhance my player model and player scoring to encompass the game state. If I do that, I would then implement a full round-robin style tournament where each player plays all the others multiple times and the players with the best overall records would be selected for the genetic evolution.
The next step in my development was to adapt my Farkle roll statistics workflow to instead generate a template for a player. The template is simply a table with the 852 different scoring dice combinations and producing it is straightforward using the dice roll generation algorithm I covered in part one. The blank player template date file is built into the other workflows to there is no need to run this workflow but if you’d like to examine it, it can be found on the hub.
Now I have everything I need to generate as many initial players’ tables as I need. Since this is just an experiment, I decide to start with 400 initial players which I will generate randomly. To create these players, I put together a KNIME workflow. This workflow uses an interesting approach to randomly select each player’s move which I’m now going to cover.
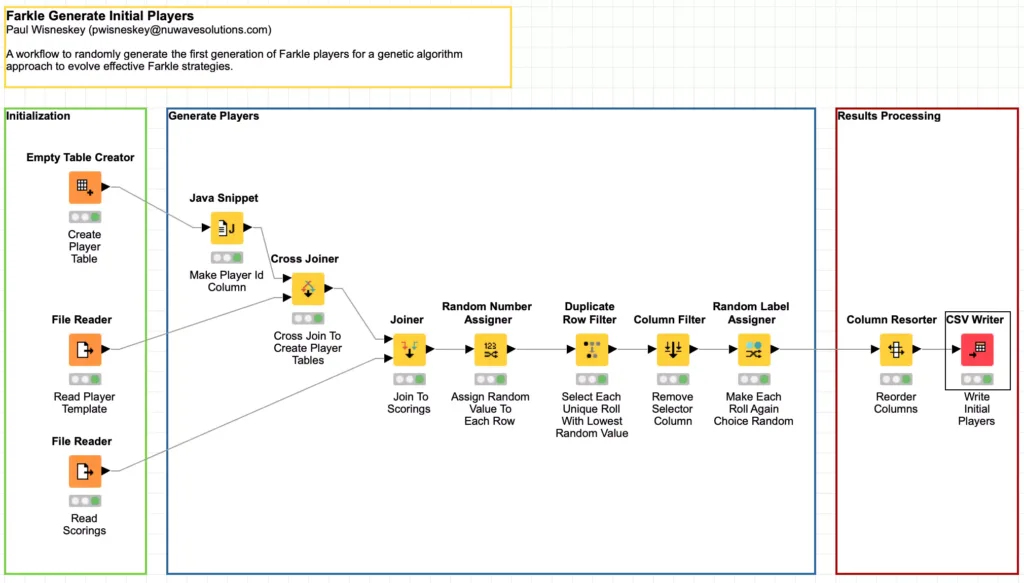
The first part of the workflow is the initialization section. This section creates an empty table with 400 rows (one row for each player). It also reads the empty player template and dice scoring data file (which represent all the possible moves a player could make). I am starting with 400 players in my initial generation because I wanted a population large enough that it would contain a wide variety of the possible player choices for each dice roll but not be so large that scoring all of the players in a generation would take an excessive amount of time.
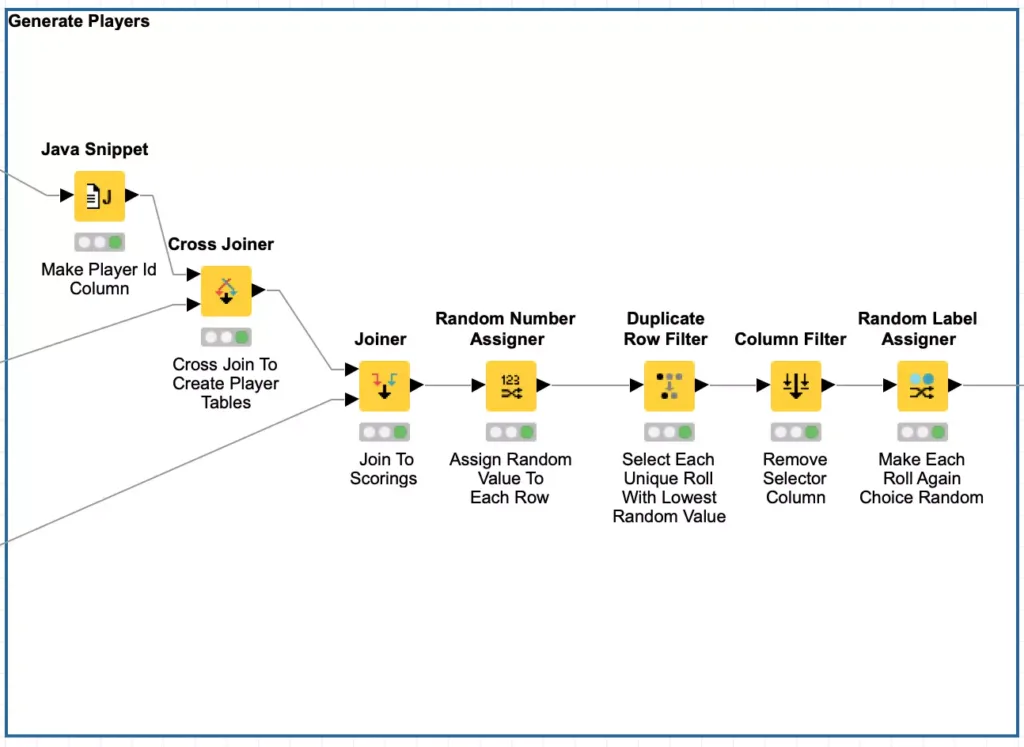
As a programmer, my first instinct for generating players is to loop over each player and generate it. This could very easily be done with KNIME’s loop node and it will work fine. But with KNIME, you should always consider if a loop is truly necessary or if it can be “unrolled” my leveraging the power of KNIME’s table-centric processing design. In a loop, the first step I would perform would be to read in the player template and assign the player id column. But if I preassign the player id to each row in my player table, I can simply cross join that table to the player template table and I will have one larger table with all player templates already present.
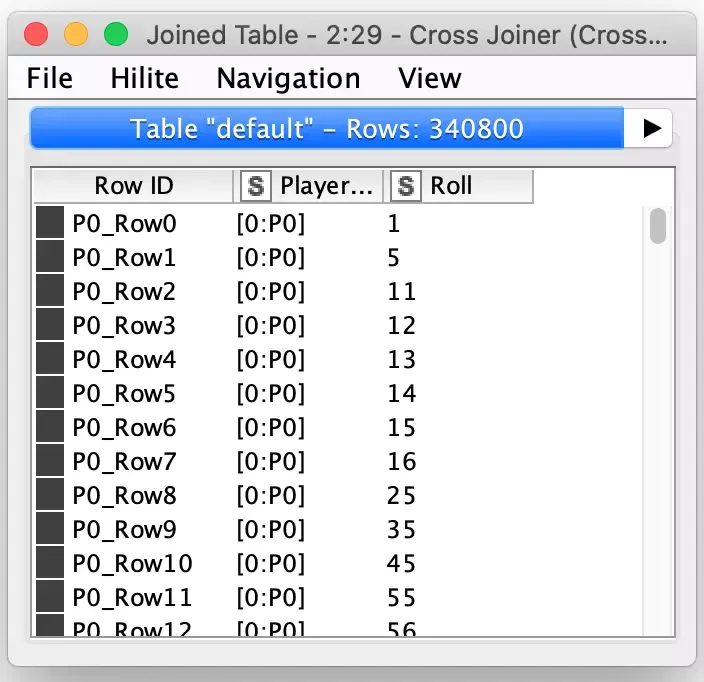
This is a much faster approach then an iterative loop which accumulates each player’s results at the end. The tradeoff is memory and storage – in this case, the cross joined table is 340,800 rows (400 players times 852 rows per player) which is the same size table that would result from a loop so there really is no memory penalty for using the cross joiner.
But the next step in a loop would be to select the moves for a player at random. To do this, I also leverage the power of KNIME’s table joining capabilities and do an inner join from the player move table to the scoring table. This has the net effect of creating rows for every possible player choice for every player and our table has grown to 1,260,000 rows but this is still well within the capacity of KNIME on my laptop. If I were worried about storage and space, I could then introduce the KNIME chunk loop nodes to process a smaller group of players at a time so that only selected moves are in the accumulated output.
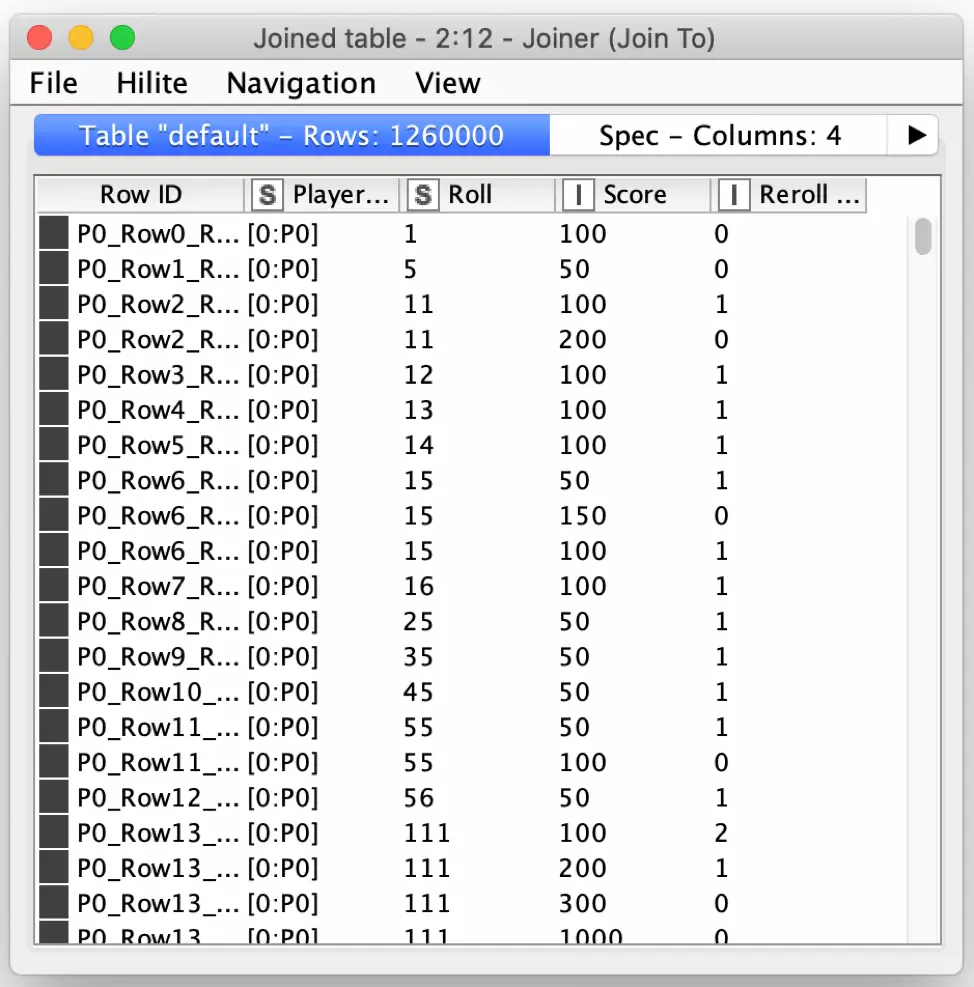
Now that I have all possible moves for the first generation of players, I need to randomly select one possible move for each dice combination so that I can reduce each player’s move records back to 852 rows and the overall table 340,800 rows again. But how to select a row at random? Again, my programmer instinct says to loop over each of the 852 dice combinations. Fortunately, my KNIME experience is there to guide me to a better solution: I can use the Random Number Assigner node to generate a new column containing a random number for each row in the entire table, which I will name the Selector column.
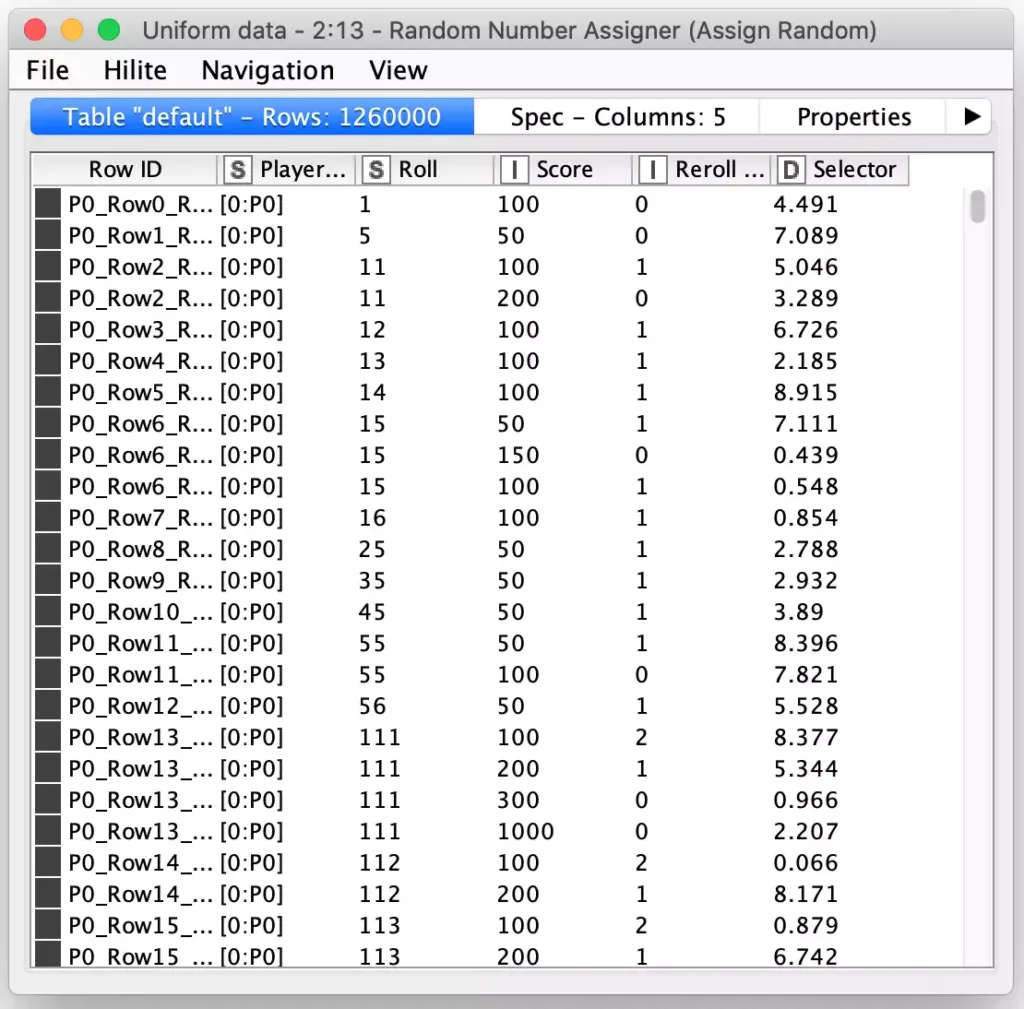
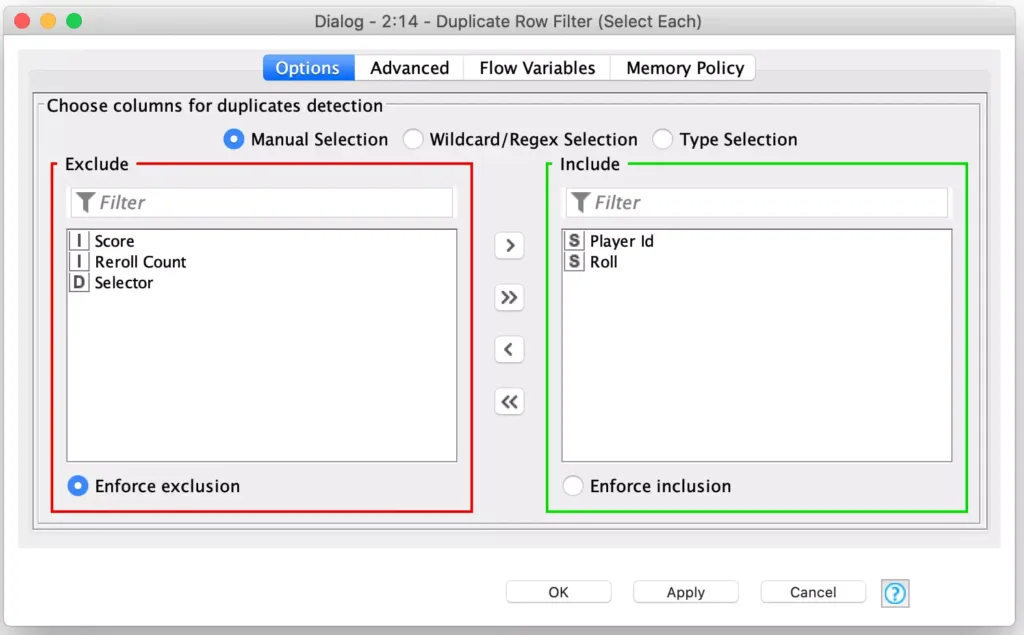
Doing this lets me use a special capability of KNIME’s Duplicate Row Filter node: this node can be configured to reduce all rows with the same value in a set of columns into a single row. But special capability is that you can also configure which of the duplicate rows to use for the values for the other columns in the retained row. I first configure the node to consider both the Player id and Roll columns for finding duplicate rows:
And then I configure the node to keep the row with the lowest value in the Selector column:
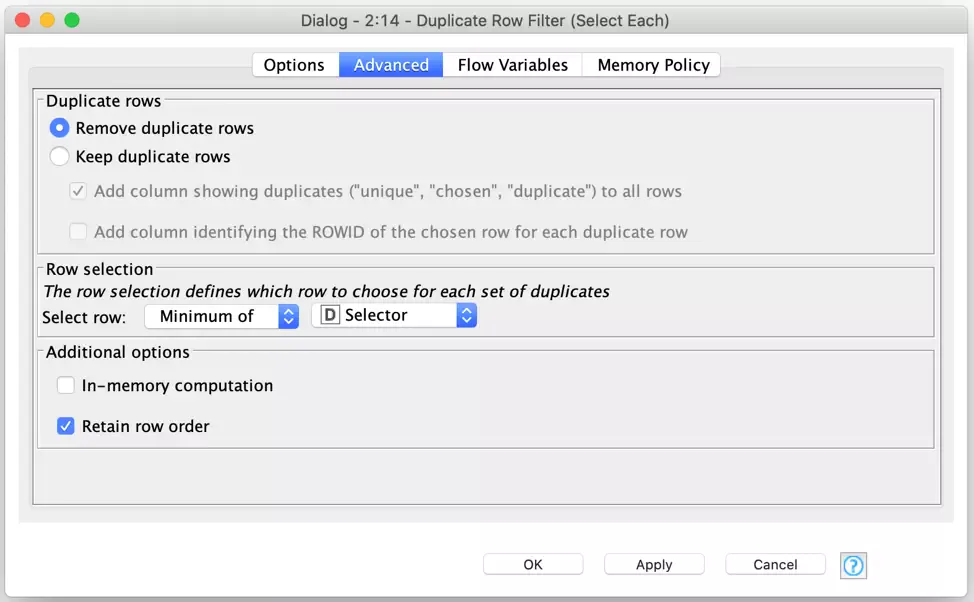
Since the value in the selector column is randomly generated, this has the net effect of randomly picking a single move for each slot in each players’ move table. And it is done in a single pass without needing to loop over each player or each dice roll (or both)!
The final step for the player generation is to create one more column which represents whether or not a player will continue to roll after making the move. This is a simple Yes or No choice and it is very easily done using KNIME’s Random Label assigner node configured to assign either choice with a 50/50 chance:
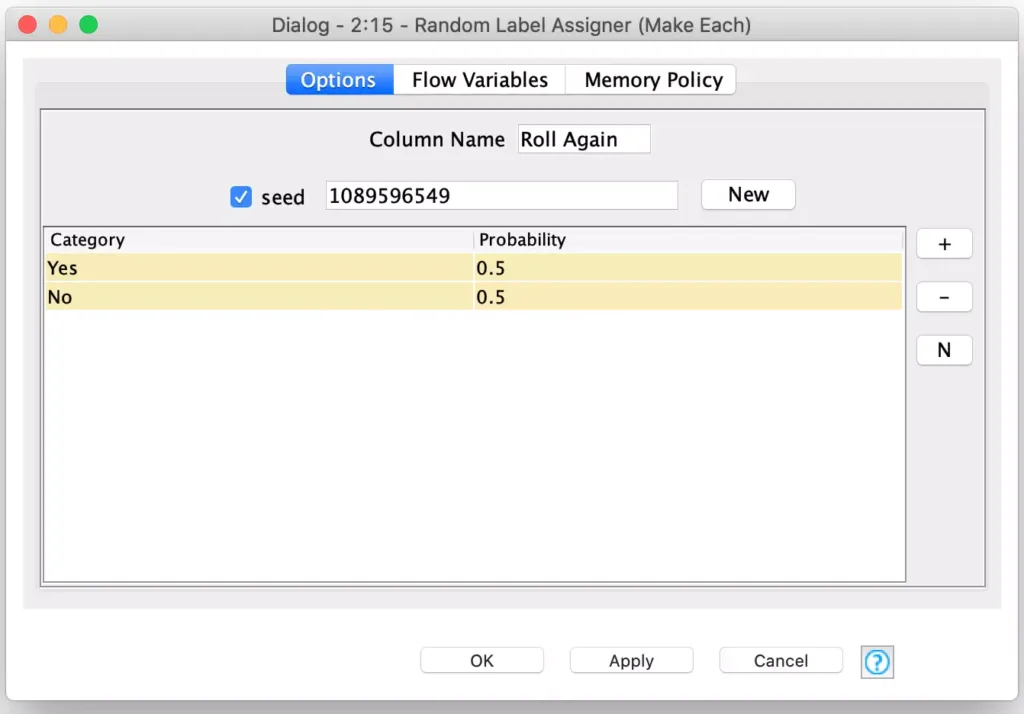
With this, I now have a complete move table for 400 players that represent my first generation of Farkle players for my genetic evolution:
In part three of this blog series, I will cover how I actually implemented the genetic algorithm to evolve these initial players towards an optimal player with, hopefully, a more effective Farkle strategy (spoiler: it worked!) In today’s posting I’ve given you some insights on how to leverage the unique capabilities of KNIME to efficiently process lots of repetitive data without resorting to myriads of nested loops. I’m saving that kind of loop nesting for the next chapter where I’ll finally show you one case where a complex loop is unavoidable but still made easy by KNIME’s Recursive Loop nodes.
Until then, keep playing Farkle and refining your own personal strategy. You are soon going to be able to play again the best descendent of my virtual Farkle evolution….

